Compartir:
Evaluar tu sistema de Generación Augmentada por Recuperación (RAG) para asegurar que cumple con los requisitos de tu negocio es crucial antes de implementarlo en entornos de producción. Sin embargo, esto requiere la adquisición de un conjunto de datos de alta calidad de pares de preguntas y respuestas del mundo real, lo que puede ser una tarea desalentadora, especialmente en las primeras etapas de desarrollo. Aquí es donde entra en juego la generación de datos sintéticos. Con Amazon Bedrock puedes generar conjuntos de datos sintéticos que emulan consultas reales de los usuarios, permitiéndote evaluar el rendimiento de tu sistema RAG de manera eficiente y a gran escala. Con datos sintéticos, puedes optimizar el proceso de evaluación y ganar confianza en las capacidades de tu sistema antes de lanzarlo al mundo real.
Este post explica cómo utilizar Anthropic Claude en Amazon Bedrock para generar datos sintéticos para evaluar tu sistema RAG. Amazon Bedrock es un servicio totalmente gestionado que ofrece una selección de modelos base (FMs) de alto rendimiento de empresas líderes en IA como AI21 Labs, Anthropic, Cohere, Meta, Stability AI, y Amazon, a través de una única API, junto con un amplio conjunto de capacidades para construir aplicaciones de IA generativa con seguridad, privacidad y ética.
Fundamentos de la Evaluación RAG
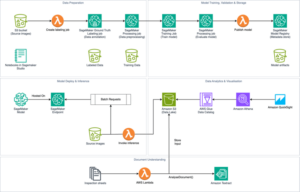
Antes de profundizar en cómo evaluar una aplicación RAG, recapitulemos los componentes básicos de un flujo de trabajo RAG simple. El flujo de trabajo consta de los siguientes pasos:
1. En la etapa de ingestión, que ocurre de forma asincrónica, los datos se dividen en fragmentos separados. Un modelo de embeddings genera embeddings para cada uno de estos fragmentos que se almacenan en un almacén de vectores.
2. Cuando el usuario hace una pregunta al sistema, se genera un embedding de la pregunta y se recuperan los fragmentos más relevantes del almacén de vectores.
3. El modelo RAG aumenta la entrada del usuario añadiendo los datos relevantes recuperados en el contexto. Esta etapa utiliza técnicas de ingeniería de prompts para comunicarse eficazmente con el modelo de lenguaje grande (LLM). El prompt aumentado permite al LLM generar una respuesta precisa a las consultas del usuario.
4. Se solicita a un LLM que formule una respuesta útil basada en las preguntas del usuario y los fragmentos recuperados.
Amazon Bedrock Knowledge Bases ofrece un enfoque simplificado para implementar RAG en AWS, proporcionando una solución completamente gestionada para conectar FMs a fuentes de datos personalizadas.
Componentes Mínimos de un Conjunto de Datos de Evaluación RAG
Para evaluar adecuadamente un sistema RAG, debes recopilar un conjunto de datos de evaluación de preguntas y respuestas típicas de los usuarios. Además, debes asegurarte de evaluar no solo la parte de generación del proceso sino también la de recuperación.
Un conjunto de datos típico de evaluación RAG consta de los siguientes componentes mínimos:
– Una lista de preguntas que los usuarios harán al sistema RAG.
– Una lista de respuestas correspondientes para evaluar la fase de generación.
– El contexto o una lista de contextos que contienen la respuesta para cada pregunta para evaluar la recuperación.
En un mundo ideal, tomarías preguntas reales de usuarios como base para la evaluación. Aunque este es el enfoque óptimo, ya que se asemeja directamente al comportamiento del usuario final, no siempre es factible, especialmente en las primeras etapas de construcción de un sistema RAG. A medida que avances, deberías aspirar a incorporar preguntas reales de usuarios en tu conjunto de evaluación.
Generación de Datos Sintéticos y su Evaluación
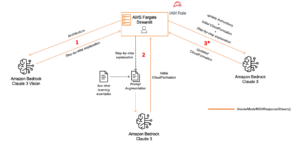
Para ilustrar el proceso, empleamos un caso de uso que construye un chatbot de cartas a los accionistas de Amazon, permitiendo a los analistas de negocios obtener información sobre la estrategia y el rendimiento de la empresa a lo largo de los años.
Primero, cargamos los archivos PDF de las cartas a los accionistas de Amazon como nuestra base de conocimiento. Mediante la implementación RAG, el recuperador de conocimiento podría usar una base de datos que soporte búsquedas vectoriales para buscar dinámicamente documentos relevantes que sirvan como fuente de conocimiento.
Utilizamos el modelo Claude de Anthropic para extraer preguntas y respuestas de nuestra fuente de conocimiento. Para la orquestación y los pasos de automatización, empleamos LangChain, una biblioteca de Python de código abierto diseñada para construir aplicaciones con modelos de lenguaje grande.
Mejores Prácticas y Conclusión
Generar datos sintéticos puede mejorar significativamente el proceso de evaluación de tu sistema RAG. Sin embargo, es esencial seguir las mejores prácticas para mantener la calidad y la representatividad de los datos generados, combinando datos sintéticos con datos reales, implementando mecanismos robustos de control de calidad y refinando continuamente el proceso.
A pesar de las limitaciones, la generación de datos sintéticos es una herramienta valiosa para acelerar el desarrollo y la evaluación de sistemas RAG, contribuyendo al desarrollo de sistemas de IA de mejor rendimiento.
Animamos a desarrolladores, investigadores y entusiastas a explorar las técnicas mencionadas y experimentar con la generación de datos sintéticos para sus propias aplicaciones RAG.