Compartir:
Los sistemas de recuperación de información han impulsado la era de la información gracias a su capacidad para rastrear y filtrar grandes cantidades de datos, devolviendo resultados precisos y relevantes rápidamente. Estos sistemas, como los motores de búsqueda y las bases de datos, generalmente funcionan indexando palabras clave y campos contenidos en archivos de datos.
Sin embargo, gran parte de nuestros datos en la era digital también provienen en formatos no textuales, como archivos de audio y video. Encontrar contenido relevante suele requerir la búsqueda a través de metadatos basados en texto, como marcas de tiempo, que deben añadirse manualmente a estos archivos. Esto puede ser difícil de escalar a medida que el volumen de archivos de audio y video no estructurados sigue creciendo.
Afortunadamente, el auge de las soluciones de inteligencia artificial (IA) que pueden transcribir audio y proporcionar capacidades de búsqueda semántica ofrece ahora soluciones más eficientes para consultar contenido de archivos de audio a escala. Amazon Transcribe es un servicio de AWS que facilita la conversión de habla a texto. Amazon Bedrock es un servicio completamente gestionado que ofrece una selección de modelos fundacionales de gran rendimiento de empresas líderes en IA a través de una única API, junto con un amplio conjunto de capacidades para construir aplicaciones de IA generativa con seguridad, privacidad e IA responsable.
En este artículo, mostramos cómo Amazon Transcribe y Amazon Bedrock pueden simplificar el proceso de catalogar, consultar y buscar a través de programas de audio, utilizando un ejemplo de la serie de podcasts AWS re:Think.
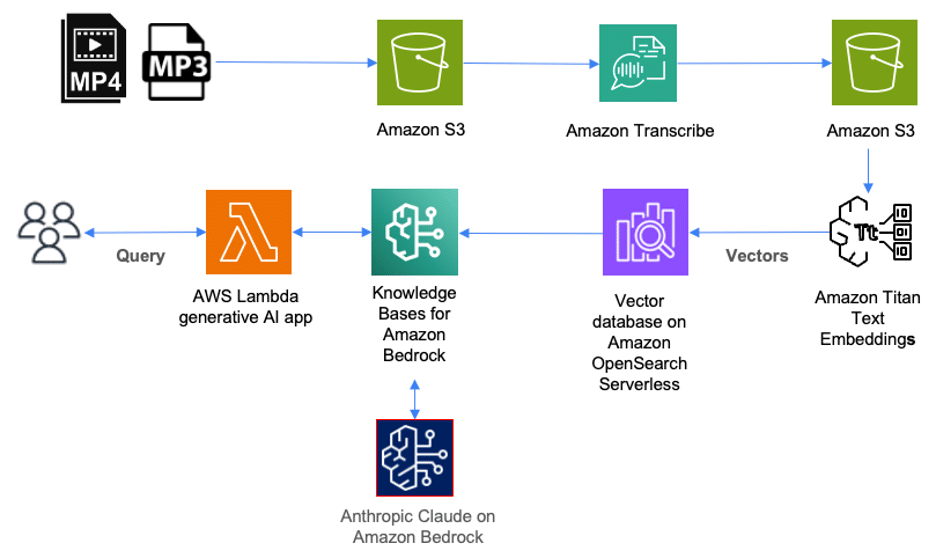
La siguiente solución ilustra cómo puede usar los servicios de AWS para desplegar una solución para catalogar, consultar y buscar a través de contenido almacenado en archivos de audio. Los archivos de audio en formato mp3 se cargan primero en Amazon Simple Storage Service (Amazon S3). Los archivos de video (como mp4) que contienen audio en idiomas compatibles también pueden ser cargados en Amazon S3 como parte de esta solución. Amazon Transcribe luego transcribirá estos archivos y almacenará la transcripción completa en formato JSON como un objeto en Amazon S3.
Para catalogar estos archivos, cada archivo JSON en Amazon S3 debe ser etiquetado con el título correspondiente del episodio. Esto nos permite recuperar el título del episodio para cada resultado de consulta. Luego, usamos Amazon Bedrock para crear representaciones numéricas del contenido dentro de cada archivo, también llamadas «embeddings», que se almacenan como vectores dentro de una base de datos de vectores que podemos consultar más tarde.
Amazon Bedrock es un servicio completamente gestionado que hace modelos fundacionales de startups líderes en IA y Amazon disponibles a través de una API. Incluido con Amazon Bedrock están las Bases de Conocimiento para Amazon Bedrock. Como un servicio completamente gestionado, las Bases de Conocimiento para Amazon Bedrock facilitan la configuración de un flujo de trabajo de Recuperación de Generación Aumentada (RAG).
Con las Bases de Conocimiento para Amazon Bedrock, primero configuramos una base de datos vectorial en AWS. Luego, este servicio puede dividir automáticamente los archivos de datos almacenados en Amazon S3 en fragmentos y crear embeddings de cada fragmento usando Amazon Titan en Amazon Bedrock. Amazon Titan es una familia de modelos fundacionales de gran rendimiento de Amazon. Junto con Amazon Titan se incluyen las Titan Text Embeddings, que utilizamos para crear la representación numérica del texto dentro de cada fragmento y almacenarlas en una base de datos vectorial.
Cuando un usuario consulta el contenido de los archivos de audio a través de una aplicación de IA generativa o una función de AWS Lambda, se hace una llamada API a las Bases de Conocimiento para Amazon Bedrock. Este servicio organiza una llamada a la base de datos vectorial para realizar una búsqueda semántica, que devuelve los resultados más relevantes. Luego, las Bases de Conocimiento para Amazon Bedrock aumentan la consulta original del usuario con estos resultados a un prompt, que se envía al modelo de lenguaje grande (LLM). El LLM devuelve resultados que son más precisos y relevantes para la consulta del usuario.
Para este ejemplo, usamos episodios de la serie de podcasts re:Think de AWS, con más de 20 episodios. Cada episodio es un programa de audio grabado en formato mp3. A medida que continuamos agregando nuevos episodios, queremos usar servicios de IA para hacer que la tarea de consultar y buscar contenido específico sea más escalable sin la necesidad de añadir metadatos manualmente para cada episodio.
Primero, necesitamos una biblioteca de archivos de audio para catalogar, consultar y buscar. Para este ejemplo, usamos episodios de la serie de podcasts AWS re:Think. Para hacer llamadas API a Amazon Bedrock desde nuestra aplicación de IA generativa, utilizamos Python versión 3.11.4 y el AWS SDK para Python (Boto3).
El primer paso es transcribir cada archivo mp3 usando Amazon Transcribe. Para instrucciones sobre transcripciones con la consola de administración de AWS o la CLI de AWS, consulte la guía para desarrolladores de Amazon Transcribe. Amazon Transcribe puede crear una transcripción para cada episodio y almacenarla como un objeto S3 en formato JSON.
Para catalogar cada episodio, etiquetamos el objeto S3 para cada episodio con el título correspondiente del episodio. Para instrucciones sobre la etiquetación de objetos en S3, consulte la Guía del Usuario de Amazon Simple Storage Service. En este ejemplo, basta con añadir la etiqueta “title” con el valor correspondiente al título del episodio.
Luego, configuramos nuestro flujo de trabajo de RAG gestionado usando las Bases de Conocimiento para Amazon Bedrock. Para instrucciones sobre la creación de una base de conocimiento, consulte la guía de usuario de Amazon Bedrock. Comenzamos especificando una fuente de datos. En nuestro caso, elegimos la ubicación del bucket S3 donde se almacenan nuestras transcripciones en formato JSON. Seleccionamos un modelo de embedding para convertir cada fragmento de nuestra transcripción en embeddings.
Las embeddings se almacenan como vectores en una base de datos vectorial. Puede especificar una base de datos vectorial existente o hacer que las Bases de Conocimiento para Amazon Bedrock cree una para usted. En este ejemplo, optamos por que el servicio cree una base de datos vectorial usando Amazon OpenSearch Serverless.
Para realizar una consulta, primero sincronizamos la base de datos vectorial con la fuente de datos. Durante cada operación de sincronización, las Bases de Conocimiento para Amazon Bedrock dividen la fuente de datos en fragmentos y usan el modelo de embedding seleccionado para embebir cada fragmento como un vector.
Luego, estamos listos para consultar y buscar contenido específico de nuestra biblioteca de episodios de podcast. Por ejemplo, preguntamos por qué AWS adquirió Annapurna Labs, y obtuvimos una respuesta precisa directamente de una cita en el episodio.
Por último, a través de API calls adicionales, podemos recuperar el título del episodio pertinente y el tiempo de inicio del contenido relevante dentro del episodio, optimizando así la experiencia de búsqueda sin necesidad de metadatos manuales exhaustivos.
Finalizando el proceso, es importante limpiar los recursos utilizados para evitar costos innecesarios, dado que los servicios operan bajo un modelo de pago por uso.
Catalogar, consultar y buscar a través de grandes volúmenes de archivos de audio puede ser difícil de escalar. Este ejemplo muestra cómo Amazon Transcribe y las Bases de Conocimiento para Amazon Bedrock pueden ayudar a automatizar y hacer más escalable el proceso de recuperar información relevante de archivos de audio.
Puede comenzar a transcribir su propia biblioteca de archivos de audio con Amazon Transcribe y utilizar las Bases de Conocimiento para Amazon Bedrock para automatizar el flujo de trabajo RAG para sus transcripciones con almacenes de vectores. Con la ayuda de estos servicios de IA, ahora podemos expandir las fronteras de nuestras bases de conocimiento.