
Compartir:
En el ámbito de la inteligencia artificial generativa, la Técnica de Recuperación Aumentada de Generación (RAG) ha surgido como una herramienta poderosa que permite a los modelos de base utilizar fuentes de conocimiento externas para una generación de texto mejorada. Amazon Bedrock es un servicio completamente gestionado que ofrece la posibilidad de elegir entre modelos de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI y Amazon a través de una única API, junto con un amplio conjunto de capacidades para desarrollar aplicaciones de inteligencia artificial generativa con seguridad, privacidad e inteligencia artificial responsable.
La capacidad de Amazon Bedrock Knowledge Bases ayuda a implementar todo el flujo de trabajo de RAG, desde la ingestión hasta la recuperación y la ampliación de los prompts, sin necesidad de construir integraciones personalizadas a fuentes de datos y gestionar flujos de datos. Sin embargo, RAG ha enfrentado desafíos, especialmente al aplicarlo para el análisis numérico, como cuando la información está incrustada en tablas anidadas complejas. Las últimas innovaciones en Amazon Bedrock Knowledge Bases proporcionan una solución a este problema.
Con RAG, se introduce un componente de recuperación de información que utiliza la entrada del usuario para extraer primero información relevante de una fuente de datos. Tanto la consulta del usuario como la información relevante se proporcionan al modelo de lenguaje grande (LLM). El LLM utiliza el nuevo conocimiento y sus datos de entrenamiento para crear mejores respuestas.
Aunque este enfoque promete mucho para documentos textuales, la presencia de elementos no textuales, como tablas, plantea un desafío significativo. Una de las dificultades es que la estructura de la tabla puede ser difícil de interpretar cuando se consulta directamente contra documentos en PDF o Word. Esto se puede abordar transformando los datos en un formato como texto, markdown o HTML. Otro problema radica en la búsqueda, recuperación y división de documentos que contienen tablas. El primer paso en RAG es dividir un documento para transformar esa parte de datos en un vector para una representación significativa del texto. Sin embargo, al aplicar este método a una tabla, incluso si se convierte en texto, existe el riesgo de que la representación vectorial no capture todas las relaciones en la tabla. Como resultado, al intentar recuperar información, se pierde mucha información y el LLM no proporciona respuestas precisas a las preguntas.
Amazon Bedrock Knowledge Bases ofrece tres capacidades para resolver este problema:
- Búsqueda híbrida: Una búsqueda híbrida recupera información basada en el significado semántico a través de representaciones vectoriales, así como a través de palabras clave. Esto permite que la información sobre campos clave específicos que antes se perdía al utilizar únicamente la búsqueda semántica, sea recuperada, y el LLM pueda proporcionar respuestas correctas de manera precisa.
- Fragmentación de datos en tamaños fijos: Se puede especificar un tamaño fijo para los datos que finalmente se transforman en un vector. Tamaños pequeños implican menores cantidades de datos y viceversa.
- Recuperación de un gran número de fragmentos de los resultados de búsqueda: Estos son la cantidad de fragmentos recuperados como resultado de la búsqueda. Cuantos más resultados se recuperen, más contexto se proporciona al LLM para obtener una respuesta.
Usar una combinación de estas características puede mejorar el análisis numérico de información en varios documentos que contienen datos en tablas. A continuación, se demuestra este enfoque utilizando un conjunto de documentos de ganancias de Amazon.
Visión general de la solución
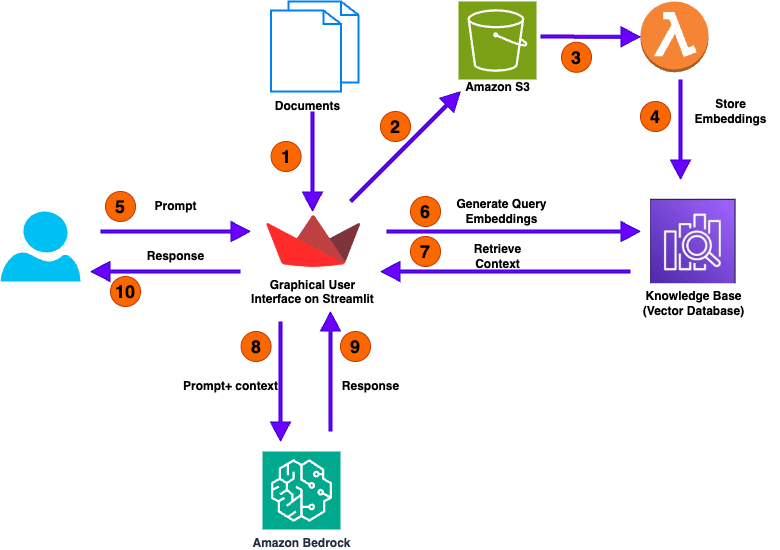
El diagrama a continuación ilustra la arquitectura a alto nivel de nuestra solución para analizar documentos numéricos.
(Imagen ilustrativa de la arquitectura del sistema)
El flujo de llamadas del usuario consiste en los siguientes pasos:
- El proceso comienza con la carga de uno o más documentos por parte del usuario, lo que inicia el flujo de trabajo.
- La aplicación Streamlit, diseñada para facilitar la interacción del usuario, toma estos documentos cargados y los almacena en un bucket de Amazon Simple Storage Service (Amazon S3).
- Después de que los documentos son copiados con éxito en el bucket de S3, el evento invoca automáticamente una función AWS Lambda.
- La función Lambda invoca la API de la base de conocimientos de Amazon Bedrock para extraer embeddings, representaciones de datos esenciales de los documentos cargados.
- Con los documentos procesados y almacenados, la interfaz gráfica de la aplicación se vuelve interactiva. Los usuarios pueden ahora interactuar con la aplicación haciendo preguntas en lenguaje natural.
- Cuando un usuario envía una pregunta, la aplicación convierte esta consulta en embeddings de consulta, encapsulando la esencia de la pregunta del usuario y ayudando a recuperar el contexto relevante de la base de conocimientos.
- Se puede usar la API Retrieve para consultar la base de conocimientos con información recuperada directamente de la misma. La API RetrieveAndGenerate utiliza los resultados recuperados para aumentar el prompt del modelo de fundamentos (FM) y devuelve la respuesta.
- Utilizando un método de búsqueda híbrida que combina técnicas basadas en palabras clave y técnicas basadas en semántica, la aplicación busca en su base de conocimientos información relevante relacionada con la consulta del usuario.
- Cuando se identifica el contexto relevante, la aplicación reenvía esta información, junto con la consulta del usuario y el contexto recuperado, al módulo LLM.
- El módulo LLM procesa la consulta y el contexto proporcionado para generar una respuesta.
- La aplicación entrega la respuesta generada al usuario a través de su GUI, completando así el ciclo de interacción.
En las siguientes secciones, detallamos los pasos para crear un bucket S3 y una base de conocimiento, desplegar la aplicación Streamlit con AWS CloudFormation y probar la solución.
vía: AWS machine learning blog









