Compartir:
La generación de vídeo se ha convertido en la última frontera en la investigación de inteligencia artificial (IA), tras el éxito de los modelos de texto a imagen. La reciente aparición de Dream Machine de Luma AI representa un avance significativo en esta área. Esta API de texto a video genera videos realistas y de alta calidad rápidamente a partir de texto e imágenes. Entrenada en Amazon SageMaker HyperPod, Dream Machine sobresale en la creación de personajes consistentes, movimientos suaves y dinámicos de la cámara.
Para acelerar la iteración y la innovación en este campo, se necesitan recursos informáticos suficientes y una plataforma escalable. Durante la fase de investigación y desarrollo iterativo, los científicos de datos y los investigadores deben ejecutar múltiples experimentos con diferentes versiones de algoritmos y escalar a modelos más grandes. El entrenamiento paralelo de modelos se vuelve necesario cuando el tamaño total del modelo excede la memoria de una sola GPU. Sin embargo, construir grandes clústeres de entrenamiento distribuidos es un proceso complejo y que requiere mucho tiempo y experiencia profunda. A medida que los clústeres se amplían a tamaños más grandes (por ejemplo, más de 32 nodos), necesitan mecanismos de resiliencia integrados, como la detección y reemplazo automáticos de nodos defectuosos, para mejorar la producción del clúster y mantener operaciones eficientes. Estos desafíos subrayan la importancia de infraestructuras robustas y sistemas de gestión en el apoyo a la investigación y desarrollo avanzados en IA.
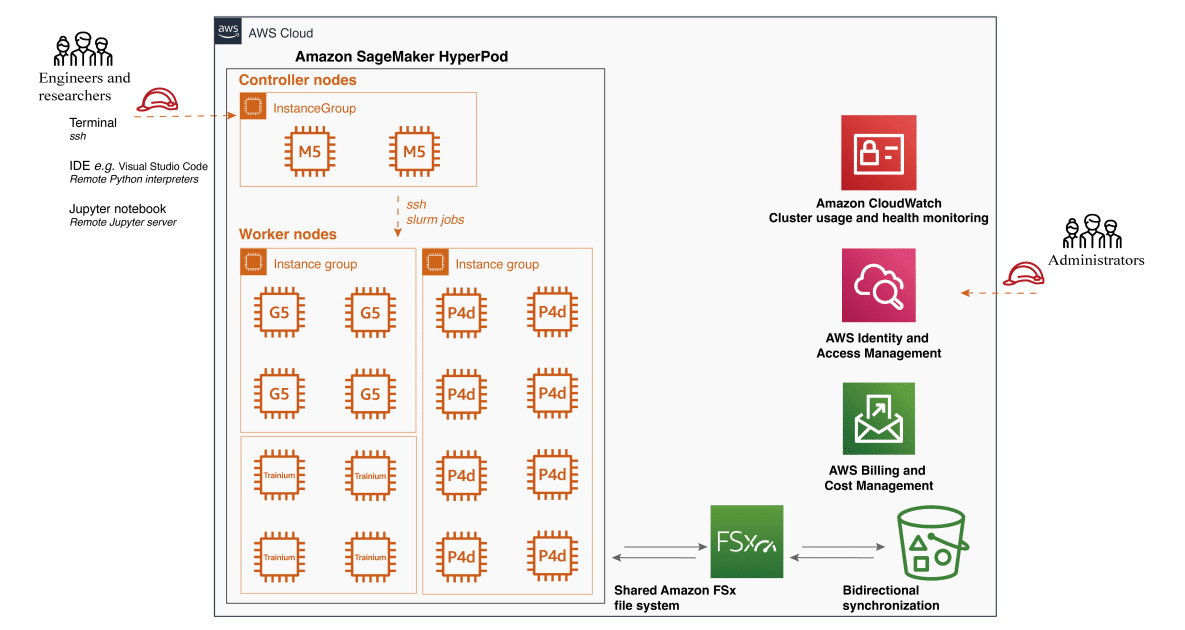
Amazon SageMaker HyperPod, presentado durante el evento re:Invent 2023, es una infraestructura diseñada para abordar los retos del entrenamiento a gran escala. Elimina el trabajo pesado no diferenciado involucrado en la construcción y optimización de infraestructuras de aprendizaje automático (ML) para entrenar modelos fundamentales (FM). SageMaker HyperPod ofrece una interfaz de usuario altamente personalizable utilizando Slurm, permitiendo a los usuarios seleccionar e instalar cualquier herramienta o marco necesario. Los clústeres se provisionan con el tipo de instancia y la cantidad de su elección y se pueden retener a lo largo de las cargas de trabajo. Con estas capacidades, los clientes están adoptando SageMaker HyperPod como su plataforma de innovación para entrenamientos de modelos más resistentes y de mayor rendimiento, permitiéndoles construir modelos de última generación más rápidamente.
En esta publicación, compartimos una arquitectura de infraestructura de ML que utiliza SageMaker HyperPod para apoyar la innovación del equipo de investigación en la generación de vídeo. Discutiremos las ventajas y puntos de dolor abordados por SageMaker HyperPod, proporcionaremos una guía de configuración paso a paso y demostraremos cómo ejecutar un algoritmo de generación de video en el clúster.
La generación de vídeo es un campo emocionante y en rápida evolución que ha visto importantes avances en los últimos años. Aunque el modelado generativo ha avanzado enormemente en el dominio de la generación de imágenes, la generación de vídeo sigue enfrentando varios desafíos que requieren mejoras adicionales.
Los modelos de difusión han hecho avances significativos en la generación de imágenes de alta calidad, lo que ha llevado a los investigadores a explorar su potencial en la generación de videos. Al aprovechar la arquitectura y las capacidades generativas preentrenadas de los modelos de difusión, los científicos buscan crear videos visualmente impresionantes. El proceso extiende las técnicas de generación de imágenes al dominio temporal, refinando iterativamente los fotogramas ruidosos, eliminando elementos aleatorios y agregando detalles significativos guiados por indicaciones de texto o imagen. Este enfoque transforma progresivamente patrones abstractos en secuencias de vídeo coherentes, traduciendo efectivamente el éxito de los modelos de difusión en la creación de imágenes estáticas a la síntesis de vídeo dinámica.
Sin embargo, los requisitos computacionales para la generación de video utilizando modelos de difusión aumentan sustancialmente en comparación con la generación de imágenes debido a varias razones. En primer lugar, se debe procesar varios fotogramas simultáneamente, añadiendo una dimensión temporal al UNet 2D original y aumentando significativamente la cantidad de datos a procesar en paralelo. Además, el proceso de difusión implica múltiples iteraciones de eliminación de ruido para cada fotograma, multiplicando la carga computacional. También se requiere un mayor número de parámetros para manejar la complejidad adicional de los datos de video, con mayores demandas computacionales y de memoria. Además, la generación de video a menudo apunta a salidas de mayor resolución y secuencias más largas en comparación con la generación de imágenes individuales, amplificando aún más los requisitos computacionales.
Los investigadores han concluido que aumentar el tamaño del modelo base conduce a mejoras sustanciales en el rendimiento de la generación de video, pero esto conlleva desafíos considerables en términos de potencia de cómputo y recursos de memoria. El entrenamiento de modelos más grandes requiere más potencia de cómputo y espacio de memoria, lo que puede limitar la accesibilidad y el uso práctico de estos modelos. Además, la manipulación de grandes conjuntos de datos necesarios para el entrenamiento implica desafíos en términos de infraestructura y costos.
Mantener la consistencia temporal y la continuidad se está haciendo cada vez más difícil a medida que aumenta la longitud del video generado. La consistencia temporal se refiere a la continuidad de elementos visuales, como objetos, personajes y escenas, a lo largo de fotogramas consecutivos. Los investigadores han explorado el uso de entradas de múltiples fotogramas, que proporcionan al modelo información sobre múltiples fotogramas consecutivos para entender y modelar mejor las relaciones y dependencias a lo largo del tiempo.
Como parte de las mejoras en la calidad de la generación de vídeo, hay un aumento significativo en el tamaño de los modelos y los datos de entrenamiento necesarios. A medida que crecen los tamaños de los modelos, los requisitos computacionales aumentan exponencialmente, dificultando entrenar estos modelos con una sola GPU o con un entorno de múltiples GPU en un solo nodo. DeepSpeed aborda estos problemas, acelerando el desarrollo y entrenamiento de modelos mediante la eliminación de redundancias de memoria a través del Particionamiento de los Tres Estados del Modelo: estados de optimizador, gradientes, y parámetros, aligerando la eficiencia de la memoria y mejorando la eficiencia de comunicación.
Integrar el clúster con Amazon Managed Service para Prometheus y Amazon Managed Grafana facilita la exportación de métricas relacionadas con los recursos del clúster, proporcionando un monitoreo integral del rendimiento, utilización y salud del sistema.
En conclusión, la utilización de SageMaker HyperPod para entrenar algoritmos de generación de vídeo representa un paso adelante significativo. Ofrece una plataforma ideal para entrenar modelos a gran escala, permitiendo gestionar clústeres con tipos y cantidades de instancias deseadas, y proporcionando flexibilidad para almacenar y recuperar datos de manera eficiente con sincronización bidireccional. La combinación de estos avances técnicos promete un futuro emocionante para el campo de la generación de vídeos.