
Compartir:
La integración de modelos de lenguaje masivo (LLM) con la técnica de Generación Aumentada con Recuperación (RAG) está revolucionando la creación de contenido, el uso de motores de búsqueda y los asistentes virtuales. Esta metodología innovadora permite a los LLM acceder a bases de conocimiento externas, optimizando la precisión y relevancia de las respuestas generadas sin necesidad de reentrenar extensamente el modelo.
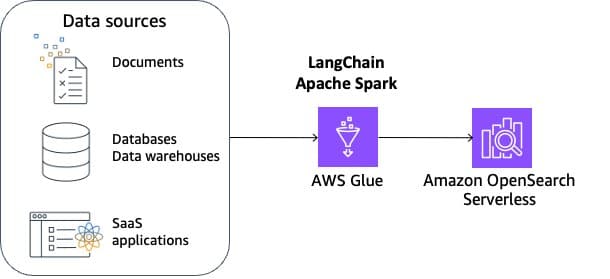
Uno de los mayores desafíos en la implementación de RAG es la ingeniería de datos necesaria para procesar y almacenar información externa en formatos diversos, como archivos o registros de bases de datos. Para superar este reto, se ha desarrollado una solución basada en LangChain, un marco de código abierto combinado con herramientas de Amazon Web Services (AWS) como AWS Glue y Amazon OpenSearch Serverless.
Esta solución establece una arquitectura de referencia para la indexación escalable de RAG, permitiendo a los equipos consumir datos variados y construir aplicaciones avanzadas que respondan preguntas complejas utilizando la base de conocimiento integrada. El proceso incluye la ingestión, transformación, vectorización y gestión de índices.
La preparación de datos, crucial para el funcionamiento responsable de RAG, se enfoca en limpiar y normalizar los documentos, mejorando la precisión de los resultados. Se implementan también consideraciones éticas y de privacidad al filtrar cuidadosamente la información. Amazon Comprehend y AWS Glue son utilizados para detectar y sanear datos sensibles antes de procesar los documentos con Spark, dividiendo la información en fragmentos manejables que pueden convertirse en incrustaciones y luego almacenarse en un índice vectorial.
Esta técnica de procesamiento no solo es innovadora, sino que permite una personalización flexible del procesamiento de datos, asegurando su calidad y relevancia en contextos específicos. Tecnologías como Apache Spark y Amazon SageMaker permiten un balance adecuado entre latencia y eficiencia de costos para las búsquedas semánticas, crucial para tareas donde la rapidez y precisión son esenciales.
En resumen, la implementación de RAG a gran escala para abrumar grandes volúmenes de datos externos representa un avance significativo en el campo de la inteligencia artificial. Esto transforma la forma en que los modelos de lenguaje pueden integrarse y utilizar información externa, ofreciendo soluciones más precisas y contextualmente relevantes.









