Compartir:
En un avance significativo en el ámbito de la inteligencia artificial y el procesamiento del lenguaje natural, las empresas están encontrando nuevas oportunidades de personalización mediante el ajuste fino de modelos de lenguaje preentrenados. Esta técnica permite adaptar estos modelos para tareas específicas, lo que resulta en una herramienta poderosa para mejorar sus capacidades.
El ajuste fino involucra la actualización de los pesos del modelo para optimizar su rendimiento en aplicaciones particulares. Esto permite que los modelos adquieran un conocimiento preciso y datos concretos, mejorando sus capacidades para tareas específicas. Sin embargo, para lograr los mejores resultados es fundamental contar con datos limpios y de alta calidad.
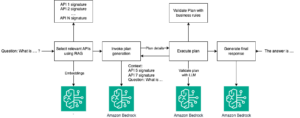
Amazon Bedrock ha introducido capacidades innovadoras para el ajuste fino de modelos de lenguaje de gran tamaño, lo que representa grandes beneficios para las empresas. Un ejemplo destacado es el modelo Claude 3 Haiku de Anthropic, que, al ser optimizado mediante esta técnica, puede superar incluso a versiones más avanzadas como Claude 3 Opus o Claude 3.5 Sonnet en ciertas aplicaciones. Esta optimización no solo mejora el rendimiento en tareas específicas, sino que también reduce costos y latencia, ofreciendo una solución eficiente y equilibrada entre capacidad y conocimiento del dominio.
A través del ajuste fino del modelo Claude 3 Haiku en Amazon Bedrock, se han identificado prácticas óptimas y lecciones valiosas. Este enfoque destaca la importancia de definir casos de uso, preparar datos, personalizar modelos y evaluar el rendimiento. Además, subraya la importancia de la optimización de hiperparámetros y la limpieza de datos para obtener resultados óptimos.
Los casos de uso ideales para el ajuste fino incluyen tareas de clasificación, generación de resultados estructurados y la adopción de tonos o lenguajes específicos para las marcas. El proceso supera el rendimiento de los modelos base en diversas aplicaciones, desde resúmenes hasta generación de lenguajes personalizados como SQL.
Un ejemplo de la eficacia del ajuste fino se observa con el dataset TAT-QA para preguntas y respuestas financieras, donde un modelo ajustado demostró significativas mejoras en rendimiento, superando los modelos base y reduciendo el uso de tokens, un logro que mejora tanto la eficiencia como la precisión de las respuestas.
La preparación y validación de datos son esenciales para asegurar la calidad en los resultados del ajuste fino. La evaluación humana y el uso de modelos masivos como jueces de calidad son métodos eficientes para mantener la integridad del conjunto de datos de entrenamiento.
El proceso de ajuste fino también incluye la personalización de entrenamientos y la evaluación del rendimiento, mostrando que los modelos ajustados consistentemente superan a los modelos base en diversos parámetros.
En conclusión, el ajuste fino de modelos de lenguaje en Amazon Bedrock proporciona considerables mejoras de rendimiento en tareas especializadas. Las organizaciones que buscan maximizar el potencial de estas tecnologías deben poner énfasis en la calidad de sus datasets, la personalización de hiperparámetros y la implementación de prácticas superiores en el ajuste fino, asegurando así su liderazgo en el avance de la inteligencia artificial.