Compartir:
Los modelos de lenguaje grandes (LLMs) están mostrando un potencial excepcional en el campo de la traducción automática, presentándose como una competencia seria para las plataformas establecidas de traducción neuronal, como Amazon Translate. Uno de los aspectos más destacados de los LLMs es su habilidad para comprender el contexto de entrada del texto, lo que les permite captar matices culturales y producir traducciones que suenen más naturales y contextuales.
Cuando se traduce una pregunta como «¿Te desempeñaste bien?», su interpretación puede variar significativamente según el idioma y el contexto cultural. Por ejemplo, en un contexto deportivo, la traducción en francés podría requerir un enfoque muy específico para asegurarse de que se mantenga la esencia cultural del mensaje original. Los LLMs, por tanto, no solo necesitan entender el contexto, sino también las particularidades culturales para lograr una traducción más precisa y fluida.
Empresas de todo el mundo están explorando cómo los LLMs pueden mejorar la calidad de su contenido traducido. La localización, combinando traducción automática con edición posterior humana (MTPE), busca optimizar la traducción no solo en términos de costo y tiempo, sino también en cuanto a la experiencia del usuario final. Sin embargo, a pesar de su potencial, los LLMs enfrentan desafíos, incluyendo calidad variable en ciertos pares de idiomas y el riesgo de generar traducciones erróneas o «alucinaciones».
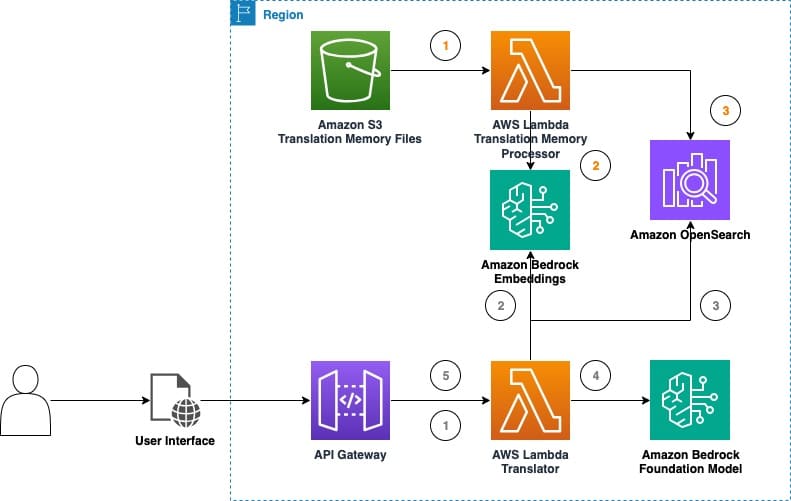
El sector de traducción se mantiene cauteloso pero optimista respecto al papel de los LLMs. Una nueva solución involucra experimentos con traducción automática en tiempo real, utilizando Amazon Bedrock, para recopilar datos sobre la eficacia de los LLMs. Esta propuesta emplea técnicas como la memoria de traducción (TM) y archivos TMX, que son cruciales en la traducción asistida por computadora. La combinación de TMs con LLMs promete no solo mejorar la exactitud de las traducciones, sino también incrementar la eficiencia del proceso.
El uso de una memoria de traducción reduce la necesidad de edición posterior, incrementando la productividad y reduciendo costos. Las empresas pueden integrar estas herramientas sin grandes complicaciones operativas, aprovechando las técnicas de aprendizaje del contexto y la ingeniería de prompts.
El llamado «parque de pruebas de traducción LLM» permite experimentar con las capacidades de estos modelos, brindando herramientas para comparar configuraciones de traducción, afectando positivamente la calidad de las traducciones gracias a la ingeniería de prompts y la generación aumentada por recuperación.
Las pruebas han demostrado que los LLMs pueden adaptarse eficientemente al contexto de las frases, mejorando tanto la calidad de la traducción como la experiencia del usuario. Los experimentos con memoria de traducción corroboraron un incremento significativo en la calidad de las traducciones, lo cual podría ser determinante en futuros proyectos de localización.
El desarrollo continuo y la exploración de los LLMs para la traducción automática no solo prometen mejorar la calidad, sino también hacer la localización más eficaz y accesible para empresas de todos los tamaños. Esta evolución podría transformar significativamente la manera en que las empresas abordan la traducción y la localización de contenido en un futuro no muy lejano.