Compartir:
La creciente demanda de integración de inteligencia artificial generativa en los negocios ha impulsado el desarrollo de soluciones innovadoras. Un método prometedor es el uso de modelos de lenguaje de gran tamaño preentrenados, como los que ofrece el servicio Amazon Bedrock. Esta plataforma gestiona modelos avanzados de diversas startups de IA y de Amazon, permitiendo a las empresas elegir el que mejor se adapte a sus necesidades.
Amazon Bedrock no solo ofrece acceso a estos modelos, sino que también permite su personalización, esencial para tareas avanzadas que requieren un enfoque específico. La personalización se logra mediante técnicas de ajuste fino, que implican entrenar un modelo preentrenado con datos etiquetados cuidadosamente para mejorar su eficacia en un uso concreto. Uno de los retos en este proceso es la dificultad de recopilar datos relevantes y de calidad.
Para superar este obstáculo, la generación de datos sintéticos ha surgido como una solución viable. Al crear datos sintéticos de entrenamiento con un modelo de lenguaje más grande, se consigue un tiempo de respuesta más rápido y se reducen los recursos necesarios, lo cual es beneficioso en escenarios con datos limitados.
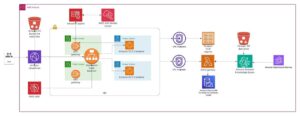
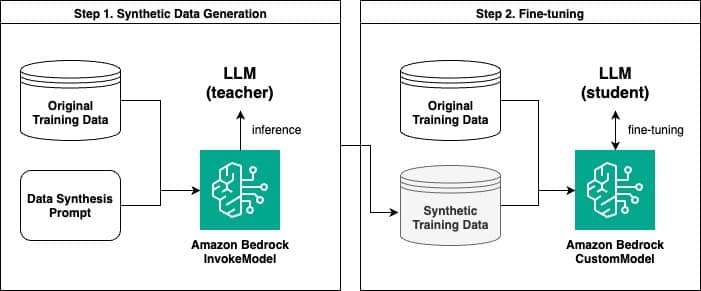
En este contexto, Amazon Bedrock permite generar datos sintéticos y ajustar modelos de lenguaje basándose en esta información. Un estudio reciente mostró cómo usar Amazon Bedrock para crear datos sintéticos y afinar un modelo. Este proceso tiene dos pasos clave: primero, generar datos sintéticos con la API InvokeModel de Amazon Bedrock y luego ajustar finamente con un modelo personalizado.
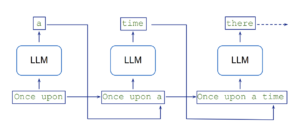
El proceso comienza generando pares de preguntas y respuestas sintéticas, donde un modelo de lenguaje más grande funciona como modelo «maestro», proporcionando información y contextos para entrenar a un modelo «estudiante» más pequeño. Este enfoque es similar a la destilación del conocimiento en el aprendizaje profundo y ha demostrado mejorar el rendimiento del modelo.
Además, se realizaron evaluaciones comparativas entre modelos afinados con datos originales y sintéticos. Los resultados revelaron que los modelos entrenados con datos sintéticos lograron, en muchos casos, un rendimiento superior, aunque no siempre superaron a aquellos entrenados con volúmenes significativos de datos originales.
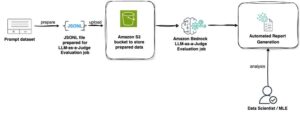
También se implementó la evaluación de modelos usando un «LLM como juez», donde un modelo de lenguaje evalúa la calidad de las respuestas generadas por otros modelos. Esta metodología mostró que los modelos afinados con ejemplos sintéticos tendían a obtener resultados destacados.
En conclusión, el uso de Amazon Bedrock para generar datos sintéticos y personalizar modelos es una estrategia eficaz para enfrentar la escasez de datos en diversas aplicaciones. A medida que las empresas buscan soluciones más eficientes y rentables en la personalización de modelos de lenguaje, estas innovaciones podrían jugar un papel clave en su desarrollo y éxito.