
Compartir:
Los modelos de lenguaje grande (LLMs) están demostrando su versatilidad en una amplia gama de tareas de procesamiento del lenguaje natural (NLP), desde diálogos simples hasta tareas más complejas como la toma de decisiones y la generación de resúmenes. A pesar de su potencial, técnicas como la ingeniería de prompts y el ajuste fino supervisado a menudo resultan insuficientes para alinear estos modelos con las intenciones del usuario. Esto puede llevar a la generación de comportamientos no deseados, como la diseminación de información errónea, malinterpretaciones o contenido tóxico.
Aunque el entrenamiento supervisado es un paso hacia la mejora de estos modelos, no logra abordar completamente las complejidades éticas y sociales que son difíciles de encapsular en ejemplos simples. Así, el ajuste supervisado puede derivar en comportamientos no intencionados que contradicen el objetivo original del modelo.
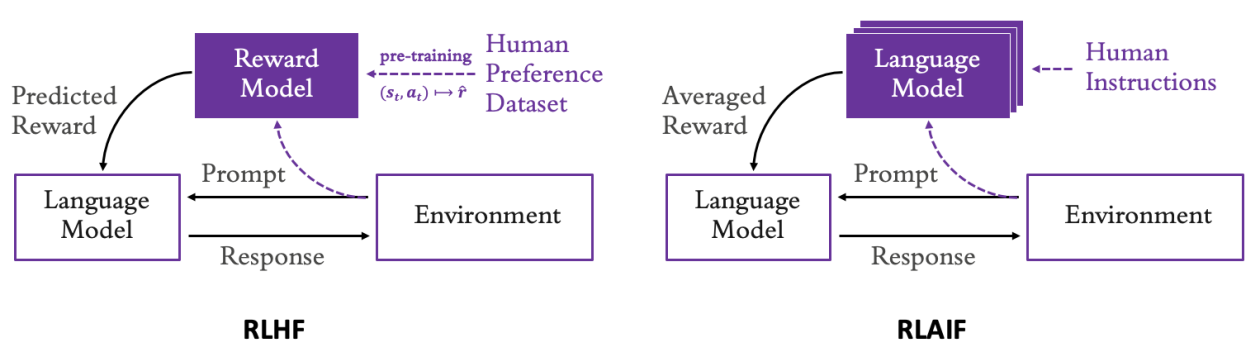
Frente a estas limitaciones, una alternativa prometedora es la utilización de modelos de recompensa entrenados con feedback humano, que permiten refinar los comportamientos de los LLMs basándose en las preferencias y valores humanos. Este enfoque, conocido como aprendizaje por refuerzo con retroalimentación humana (RLHF, por sus siglas en inglés), está ganando tracción. Además, recientes estudios han señalado que la retroalimentación directa de otros modelos de lenguaje podría escalar eficazmente el desarrollo de modelos de recompensa, en un proceso denominado superalineación mediante retroalimentación de IA (RLAIF).
La técnica de RLAIF permite la utilización de múltiples LLMs, cada uno especializado en distintos aspectos de las preferencias humanas, como relevancia, concisión o toxicidad. Esto evita la necesidad de servicios de anotación humana, haciendo el proceso más eficiente. El enfoque ha demostrado potencial en la creación de sistemas que continúan siendo útiles, honestos y no perjudiciales, incluso cuando las capacidades de IA alcanzan o superan el rendimiento humano.
Un caso práctico de RLAIF puede involucrar la generación de respuestas en un conjunto de datos de diálogos, con el objetivo de minimizar la toxicidad en las respuestas creadas. Para lograrlo, se pueden emplear modelos de recompensa ya disponibles públicamente para el ajuste fino de LLMs, evaluando el éxito de este ajuste con pruebas en un conjunto de datos reservado.
En resumen, el desarrollo y ajuste de LLMs sigue siendo un campo dinámico y en constante evolución, donde enfoques como RLAIF ofrecen nuevas oportunidades para mejorar la alineación de la IA con las preferencias y valores humanos. Esto asegura respuestas más útiles y menos perjudiciales, mientras se enfrentan los desafíos éticos y técnicos asociados con la inteligencia artificial moderna.









