
Compartir:
En el dinámico campo de la inteligencia artificial, la optimización de modelos base representa un avance crucial para mejorar la comprensión y precisión en diversas aplicaciones. Recientemente, un experimento innovador ha destacado el uso de Amazon SageMaker Autopilot y el SDK AutoMLV2 para afinar un modelo Meta Llama2-7B en tareas de respuesta a preguntas, específicamente en exámenes de ciencias que abarcan disciplinas como física, química y biología.
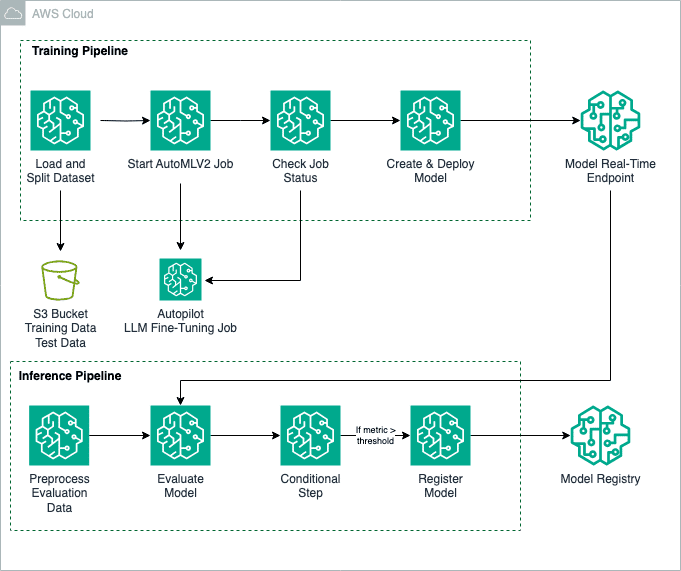
Este proceso no se limita únicamente a la respuesta a preguntas; también es aplicable a otros ámbitos como la generación de resúmenes y la producción de textos en sectores como atención médica, educación y servicios financieros. La funcionalidad de AutoMLV2 permite un ajuste preciso de una variedad de modelos base utilizando Amazon SageMaker JumpStart. Para automatizar el flujo de trabajo completo, desde la preparación de datos hasta la creación y ajuste del modelo, se emplea Amazon SageMaker Pipelines.
El proceso de ajuste emplea el conjunto de datos SciQ, un repositorio de preguntas de examen orientado a las ciencias, para entrenar el modelo Llama2-7B. Estos datos se preparan y dividen en archivos CSV, organizando columnas que representan tanto las preguntas como las respuestas correctas. Este cuidadoso formato asegura compatibilidad total con SageMaker Autopilot.
Para personalizar el proceso de ajuste fino, se configuran varios parámetros como el modelo base, la aceptación del EULA y diferentes hiperparámetros, que optimizan múltiples aspectos del aprendizaje del modelo, tales como el número de épocas y la tasa de aprendizaje. Este nivel de personalización permite al modelo abordar eficazmente los problemas específicos de la tarea.
Una vez completado el ajuste fino, el modelo se despliega en un punto de inferencia en tiempo real, lo que proporciona resultados al instante. La evaluación del rendimiento se realiza con la biblioteca fmeval, una herramienta que mide métricas personalizadas, garantizando que el modelo opere adecuadamente en escenarios reales.
Este enfoque no solo incrementa la precisión del modelo para la tarea designada, sino que también optimiza el proceso de despliegue y evaluación. Además, se asegura un alto control de calidad mediante la evaluación rigurosa de métricas de rendimiento, asegurando que solo los modelos más eficientes se registren y desplieguen en producción.
En conjunto, este proceso automatizado representa un avance significativo hacia la implementación eficiente de modelos de lenguaje a gran escala, facilitando su integración en sistemas que requieren inferencias precisas y relevantes en tiempo real.









