Compartir:
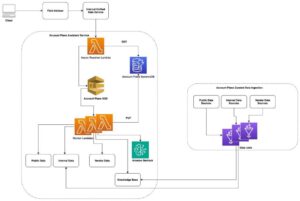
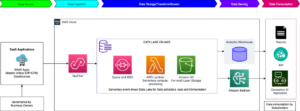
Amazon ha lanzado una serie de funciones avanzadas para su servicio Knowledge Bases for Amazon Bedrock, diseñado para optimizar los flujos de trabajo de Retrieval Augmented Generation (RAG). Esta plataforma completamente gestionada permite implementar todo el flujo de trabajo de RAG, desde la ingesta hasta la recuperación y actualización de consultas, sin necesidad de integraciones personalizadas.
Uno de los mayores desafíos en las aplicaciones basadas en RAG es manejar documentos de texto grandes o complejos, como PDFs. La necesidad de técnicas avanzadas de fragmentación de datos es esencial para representar correctamente las relaciones semánticas en dichos documentos. Las nuevas funcionalidades, como la fragmentación semántica y jerárquica, junto con mejoras en el análisis de CSV y PDF, están diseñadas para mejorar la precisión en la recuperación de información.
El análisis avanzado desglosa documentos complejos en partes significativas, identificando relaciones entre texto, tablas e imágenes. Empleando modelos fundacionales (FMs), el servicio puede interpretar datos complejos, como tablas anidadas o texto dentro de imágenes, lo cual mejora la extracción de información y la generación de respuestas relevantes.
Knowledge Bases for Amazon Bedrock ahora ofrece nuevas técnicas de fragmentación, incluyendo la fragmentación semántica y jerárquica. La fragmentación semántica divide el texto según su significado, manteniendo la integridad del contexto y mejorando la calidad de la recuperación. Por otro lado, la fragmentación jerárquica organiza los datos en una estructura jerárquica que permite una recuperación más granular y eficiente, basándose en las relaciones inherentes dentro de los datos.
Para usuarios que necesitan mayor control, el servicio ofrece la capacidad de definir lógica de procesamiento personalizada utilizando funciones AWS Lambda. Esto permite a los usuarios aplicar metodologías de fragmentación específicas y procesar metadatos adicionales, adaptándose mejor a sus requisitos específicos.
Las mejoras en el procesamiento de archivos CSV permiten especificar campos de contenido y metadatos por separado, facilitando la gestión de grandes conjuntos de datos y mejorando la limpieza y normalización de datos.
Para consultas complejas, el servicio ahora soporta la descomposición de consultas en subconsultas más manejables, mejorando la precisión de las respuestas al reducir la complejidad semántica de las consultas iniciales. Esta función se puede habilitar tanto desde la consola como a través de la API.
Con estas nuevas características, Knowledge Bases for Amazon Bedrock se posiciona como una solución poderosa y versátil para implementar flujos de trabajo de RAG, ofreciendo herramientas y capacidades que permiten a las organizaciones maximizar el potencial de sus bases de conocimiento y mejorar la toma de decisiones basada en datos.