Compartir:
Hoy, Amazon ha anunciado la disponibilidad de los modelos Llama 3.2 en Amazon SageMaker JumpStart y Amazon Bedrock. Los modelos Llama 3.2 representan una colección de avanzados modelos de inteligencia artificial generativa, pre-entrenados y ajustados mediante instrucciones. Estos modelos están disponibles en diversas configuraciones, desde ligeros modelos de solo texto con 1.000 millones (1B) y 3.000 millones (3B) de parámetros, adecuados para dispositivos periféricos, hasta modelos más robustos de 11.000 millones (11B) y 90.000 millones (90B) de parámetros, capaces de realizar tareas de razonamiento sofisticado, incluyendo soporte multimodal para imágenes de alta resolución.
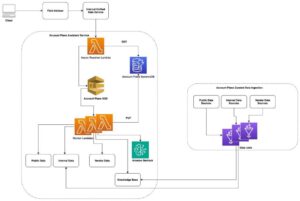
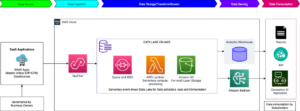
SageMaker JumpStart es una plataforma de aprendizaje automático que proporciona acceso a algoritmos, modelos y soluciones de ML para que los usuarios puedan comenzar rápidamente. Por su parte, Amazon Bedrock es un servicio totalmente gestionado que ofrece una selección de modelos fundacionales de alto rendimiento de compañías líderes en IA, como Meta, mediante una sola API, junto con un conjunto amplio de capacidades necesarias para construir aplicaciones de IA generativa con seguridad, privacidad y responsabilidad.
En un reciente comunicado, Amazon ha demostrado cómo utilizar los modelos Llama 3.2 11B y 90B para diversos casos de uso basados en visión. Esta es la primera vez que los modelos Llama de Meta se lanzan con capacidades de visión, ampliando así la aplicabilidad de estos modelos más allá de las aplicaciones tradicionales solo de texto. Los casos de uso basados en visión discutidos incluyen respuesta a preguntas visuales de documentos, extracción de información estructurada de imágenes y generación de subtítulos para imágenes.
Los modelos Llama 3.2 11B y 90B son multimodales, ya que admiten entrada y salida de texto, así como entrada de texto e imagen y salida de texto. Estos modelos son los primeros de la serie Llama en soportar tareas de visión, con una arquitectura de modelo nueva que integra representaciones del codificador de imágenes en el modelo de lenguaje. Están diseñados para ser más eficientes en cargas de trabajo de IA, con una latencia reducida y un rendimiento mejorado, lo que los hace adecuados para una amplia gama de aplicaciones. Además, todos los modelos Llama 3.2 admiten una longitud de contexto de 128.000 tokens, manteniendo la capacidad de tokens ampliada introducida en Llama 3.1, y ofrecen mejor soporte multilingüe para ocho idiomas: inglés, alemán, francés, italiano, portugués, hindi, español y tailandés.
Los modelos Llama 3.2 ya están disponibles para inferencias en SageMaker JumpStart y Amazon Bedrock. En SageMaker JumpStart, se puede acceder a estos modelos inicialmente en la región AWS US East (Ohio) y soportan los tipos de instancias requeridos. Los modelos Llama 3.2 90B y 11B de Meta también están disponibles en Amazon Bedrock en las regiones US West (Oregon) y US East (Ohio, N. Virginia) mediante inferencia entre regiones. Los modelos Llama 3.2 1B y 3B están disponibles en las regiones US West (Oregon) y Europa (Frankfurt), y en las regiones US East (Ohio, N. Virginia) y Europa (Irlanda, París) con disponibilidad regional ampliada planificada para el futuro.
Además de su integración en SageMaker y Bedrock, se han presentado diversos ejemplos de uso práctico de los modelos Llama 3.2 en tareas como respuesta a preguntas sobre documentos, extracción de entidades y generación de subtítulos, demostrando su amplio potencial y utilidad en industrias como el comercio electrónico, el marketing y más.