Compartir:
Webex de Cisco se ha consolidado como un líder en soluciones de colaboración basadas en la nube, ofreciendo una amplia gama de servicios que incluyen reuniones por video, llamadas, mensajería, eventos, encuestas, video asincrónico y soluciones para experiencia del cliente, como centros de contacto y dispositivos diseñados para la colaboración. Su enfoque en ofrecer experiencias inclusivas de colaboración impulsa su innovación, que utiliza IA y aprendizaje automático para eliminar barreras geográficas, de idioma, de personalidad y de familiaridad con la tecnología. Además, sus soluciones están concebidas con seguridad y privacidad desde el diseño.
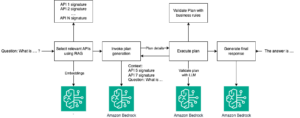
El equipo de Webex AI (WxAI) de Cisco ha sido crucial en la mejora de estos productos mediante funciones y características impulsadas por IA. En el último año, han centrado sus esfuerzos en desarrollar capacidades de inteligencia artificial (AI) basadas en modelos de lenguaje de gran tamaño (LLMs) para mejorar la productividad y la experiencia de los usuarios. Un área destacada es el Webex Contact Center, una solución de centro de contacto omnicanal en la nube que permite a las organizaciones brindar experiencias excepcionales a los clientes. Mediante la integración de LLMs, el equipo de WxAI ha habilitado capacidades avanzadas como asistentes virtuales inteligentes, procesamiento del lenguaje natural y análisis de sentimientos, lo que permite al Webex Contact Center ofrecer un soporte más personalizado y eficiente.
Sin embargo, a medida que los modelos de LLM crecían hasta contener cientos de gigabytes de datos, el equipo de WxAI se enfrentó a desafíos en la asignación eficiente de recursos y el inicio de aplicaciones con modelos incorporados. Para optimizar su infraestructura de IA/ML, Cisco migró sus LLMs a Amazon SageMaker Inference, mejorando la velocidad, escalabilidad y rendimiento en términos de costo.
Webex está aplicando IA generativa en sus soluciones de centros de contacto, permitiendo conversaciones más naturales y humanas entre clientes y agentes. La IA puede generar respuestas contextuales y empáticas a las consultas de los clientes, así como redactar automáticamente correos electrónicos y mensajes de chat personalizados. Esto ayuda a los agentes de los centros de contacto a trabajar de manera más eficiente sin comprometer la calidad del servicio al cliente.
Inicialmente, el equipo de WxAI incorporaba modelos de LLM directamente en las imágenes de contenedores de aplicaciones que se ejecutaban en Amazon Elastic Kubernetes Service (Amazon EKS). Sin embargo, a medida que los modelos se volvían más grandes y complejos, este enfoque enfrentaba desafíos significativos de escalabilidad y utilización de recursos. La operación de los modelos de LLM, que demandan muchos recursos, a través de las aplicaciones requería la provisión de grandes recursos computacionales, lo que ralentizaba procesos como la asignación de recursos y el inicio de aplicaciones. Esta ineficiencia limitaba la capacidad del equipo de WxAI para desarrollar, probar y desplegar rápidamente nuevas funciones impulsadas por IA para la cartera de Webex.
Para abordar estos desafíos, el equipo de WxAI recurrió a SageMaker Inference, un servicio de inferencia de IA totalmente gestionado que permite el despliegue y la escalabilidad sin problemas de modelos independientemente de las aplicaciones que los utilizan. Al desacoplar el alojamiento de los LLMs de las aplicaciones de Webex, el equipo de WxAI pudo provisionar los recursos computacionales necesarios para los modelos sin afectar las capacidades básicas de colaboración y comunicación.
La implementación de modelos en SageMaker ha permitido a Webex explotar el poder de la IA generativa en toda su gama de soluciones de colaboración y compromiso con el cliente. Este cambio arquitectónico ha facilitado la adopción del escalado automático a alta velocidad, esencial para gestionar la inferencia de IA generativa en tiempo real. Los resultados han mostrado una mejora significativa en la latencia de la inferencia, llegando a reducirla hasta en un 50%.
Este avance no solo ha mejorado la eficiencia y el rendimiento de las aplicaciones críticas de IA generativa de Cisco, sino que también ha preparado el camino para futuros desarrollos e integraciones de IA aún más avanzadas. La colaboración entre Cisco y Amazon SageMaker continúa siendo fundamental para llevar estas innovaciones a las soluciones de colaboración de Webex, asegurando que los usuarios disfruten de experiencias cada vez más ricas y eficientes.