Compartir:
La proliferación de modelos de lenguaje grande (LLMs) en los entornos de TI empresariales presenta nuevos desafíos y oportunidades en términos de seguridad, inteligencia artificial (IA) responsable, privacidad y la ingeniería de prompts. Los riesgos asociados con el uso de LLM, como salidas sesgadas, violaciones de privacidad y vulnerabilidades de seguridad, deben ser mitigados. Para abordar estos desafíos, las organizaciones deben asegurarse proactivamente de que su uso de LLMs se alinee con los principios más amplios de la IA responsable y prioricen la seguridad y privacidad. Al trabajar con LLMs, las organizaciones deben definir objetivos e implementar medidas para mejorar la seguridad de sus implementaciones LLM, tal como lo hacen con el cumplimiento normativo aplicable.
Esto implica desplegar mecanismos robustos de autenticación, protocolos de encriptación y diseños optimizados de prompts para identificar y contrarrestar intentos de inyección de prompts, filtrado de prompts y jailbreaking, lo que puede ayudar a incrementar la fiabilidad de las salidas generadas por IA en relación con la seguridad.
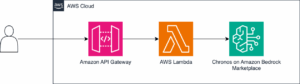
Este artículo discute las amenazas existentes a nivel de prompts y describe varios mecanismos de seguridad para mitigar estas amenazas. En nuestro ejemplo, trabajamos con Anthropic Claude en Amazon Bedrock, implementando plantillas de prompts que nos permiten imponer medidas de seguridad contra amenazas comunes como la inyección de prompts. Estas plantillas son compatibles y pueden ser modificadas para otros LLMs.
Los LLMs están entrenados a una escala sin precedentes, con algunos de los modelos más grandes comprendiendo miles de millones de parámetros y consumiendo terabytes de datos textuales de diversas fuentes. Esta escala masiva permite a los LLMs desarrollar una comprensión rica y matizada del lenguaje, capturando sutilezas, modismos y señales contextuales que anteriormente eran desafiantes para los sistemas de IA.
Para utilizar estos modelos, se pueden recurrir a servicios como Amazon Bedrock, que proporciona acceso a una variedad de modelos fundamentales tanto de Amazon como de proveedores terceros, incluyendo Anthropic, Cohere, Meta, entre otros. Amazon Bedrock permite experimentar con modelos de última generación, personalizarlos y ajustarlos para incorporarlos en soluciones potenciadas por la IA generativa a través de una sola API.
Una limitación significativa de los LLMs es su incapacidad para incorporar conocimientos más allá de los presentes en sus datos de entrenamiento. Aunque los LLMs sobresalen en capturar patrones y generar texto coherente, a menudo carecen de acceso a información actualizada o especializada, lo que limita su utilidad en aplicaciones del mundo real. Un caso de uso que aborda esta limitación es la Generación Aumentada por Recuperación (RAG). RAG combina el poder de los LLMs con un componente de recuperación que puede acceder e incorporar información relevante de fuentes externas, como bases de conocimientos, sistemas de búsqueda inteligente y bases de datos vectoriales.
En su núcleo, RAG emplea un proceso de dos etapas. En la primera etapa, un componente de recuperación identifica y recupera documentos o pasajes textuales relevantes basados en la consulta de entrada. Estos se utilizan para aumentar el contenido del prompt original y se pasan a un LLM. El LLM luego genera una respuesta al prompt aumentado basada en la consulta y la información recuperada. Este enfoque híbrido permite a RAG aprovechar las fortalezas tanto de los LLMs como de los sistemas de recuperación, permitiendo la generación de respuestas más precisas e informadas que incorporan conocimientos actualizados y especializados.
LLMs y aplicaciones RAG orientadas al usuario, como los chatbots de respuesta a preguntas, están expuestas a muchas vulnerabilidades de seguridad. Central para el uso responsable de los LLMs es la mitigación de amenazas a nivel de prompts mediante el uso de medidas de seguridad. Estas pueden aplicarse para filtros de contenido y temas a aplicaciones impulsadas por Amazon Bedrock, así como la mitigación de amenazas de prompts a través de la etiquetación y el filtrado de entradas de usuario.
Los modelos de lenguaje grande también deben emplear la ingeniería de prompts en procesos de desarrollo de IA junto con las medidas de seguridad para mitigar vulnerabilidades de inyección de prompts y mantener principios de equidad, transparencia y privacidad en aplicaciones LLM. Todas estas salvaguardias, usadas en conjunto, ayudan a construir una aplicación potente y segura potenciadas por LLM, protegida ante amenazas de seguridad comunes.
Como conclusión, propusimos una serie de medidas de seguridad en la ingeniería de prompts y recomendaciones para mitigar amenazas a niveles de prompts, demostrando la eficacia de estas medidas en nuestra evaluación de seguridad. Animamos a los lectores a aplicar estos aprendizajes y comenzar a construir soluciones de IA generativa más seguras en Amazon Bedrock.