
Compartir:
BRIA AI ha desarrollado recientemente una versión avanzada de su modelo de difusión de texto a imagen, logrando una resolución de 1024×1024 píxeles. Este modelo, conocido como BRIA AI 2.0, se entrenó utilizando un extenso conjunto de datos compuesto por petabytes de imágenes licenciadas, procedentes de socios como Getty Images, DepositPhotos y Alamy. Este proceso de entrenamiento de alta capacidad fue facilitado de manera eficiente y económica gracias a Amazon SageMaker, que se encargó de la gestión de la infraestructura necesaria.
BRIA AI se posiciona como una plataforma líder en inteligencia artificial generativa, ofreciendo modelos avanzados exclusivamente entrenados en datos con licencia, y diseñados para ser integrados de manera segura y optimizada en distintas arquitecturas tecnológicas. Su suite de modelos generativos está dirigida a grandes marcas, estudios de animación y videojuegos, y agencias de marketing, colocando un énfasis especial en la obtención ética de datos y en la preparación comercial de sus productos.
El proceso de entrenamiento implicó superar diversos desafíos, entre los que destaca la necesidad de excelencia operativa, reducir el tiempo de entrenamiento mediante el uso del paralelismo de datos, maximizar la utilización de GPU mediante una carga de datos eficiente y reducir el coste del entrenamiento, pagando solamente por el tiempo neto de entrenamiento. Todo esto fue posible manteniendo la pila de software inicial que utilizaba BRIA AI, Accelerate de HuggingFace, sin requerir modificaciones en la implementación del modelo o en el código de entrenamiento.
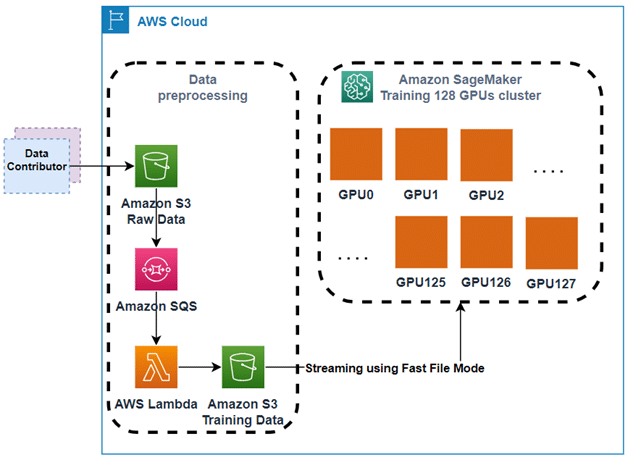
En términos de arquitectura, el pipeline de entrenamiento de BRIA AI consta de dos componentes principales: la preprocesamiento de datos y el entrenamiento del modelo. Los contribuyentes de datos suben las imágenes en bruto a un bucket de Amazon S3, donde se procesa la generación de metadatos de las imágenes y se empaqueta la data de entrenamiento en archivos webdataset para una eficiente transmisión de datos desde el bucket de S3 y su distribución en varias GPUs. El entrenamiento del modelo se lleva a cabo mediante trabajos distribuidos de SageMaker, que gestiona el clúster de entrenamiento y transmite datos desde S3 a las instancias de entrenamiento usando el modo FastFile de SageMaker.
Uno de los principales retos resueltos fue la gestión eficiente del almacenamiento y transmisión de datos de millones de imágenes, optando por una modalidad de acceso rápido a archivos que mejora significativamente los tiempos de carga y evita el cuello de botella al manejar un gran volumen de pequeños archivos de imagen. Además, el uso de SageMaker permitió a BRIA AI pagar sólo por el tiempo de entrenamiento activo, optimizando los costes y la eficiencia.
El resultado fue un modelo entrenado de manera eficiente, con un uso de GPU promedio superior al 98% y una reducción significativa del tiempo de entrenamiento gracias al paralelismo de datos y a la infraestructura proporcionada por SageMaker. Este enfoque permitió a BRIA AI realizar innovaciones más rápidas y productivas, subvencionadas por las facilidades y automatizaciones de Amazon SageMaker.
BRIA AI y AWS han ejemplificado cómo la cooperación y uso de tecnología avanzada pueden superar los desafíos técnicos de entrenar modelos de inteligencia artificial a gran escala, manteniendo al equipo enfocado en innovaciones creativas y entregando resultados sobresalientes en menor tiempo y a menor costo.









