Compartir:
Con la llegada de soluciones de inteligencia artificial generativa, se está produciendo un cambio de paradigma en diversas industrias, impulsado por organizaciones que adoptan modelos base para desbloquear oportunidades sin precedentes. Amazon Bedrock se ha consolidado como la opción preferida para numerosos clientes que buscan innovar y lanzar aplicaciones de IA generativa, lo que ha llevado a un aumento exponencial en la demanda de capacidades de inferencia de modelos. Los clientes de Bedrock tienen como objetivo escalar sus aplicaciones a nivel mundial para acomodar el crecimiento y requieren capacidad adicional para manejar picos inesperados de tráfico. Actualmente, los usuarios pueden tener que diseñar sus aplicaciones para manejar escenarios de picos de tráfico, utilizando cuotas de servicio de múltiples regiones mediante técnicas complejas, como el balanceo de carga del lado del cliente entre regiones de AWS. Sin embargo, esta naturaleza dinámica de la demanda es difícil de predecir, aumenta la sobrecarga operativa e introduce puntos potenciales de falla, lo que puede impedir que las empresas logren una verdadera resiliencia global y disponibilidad continua de servicio.
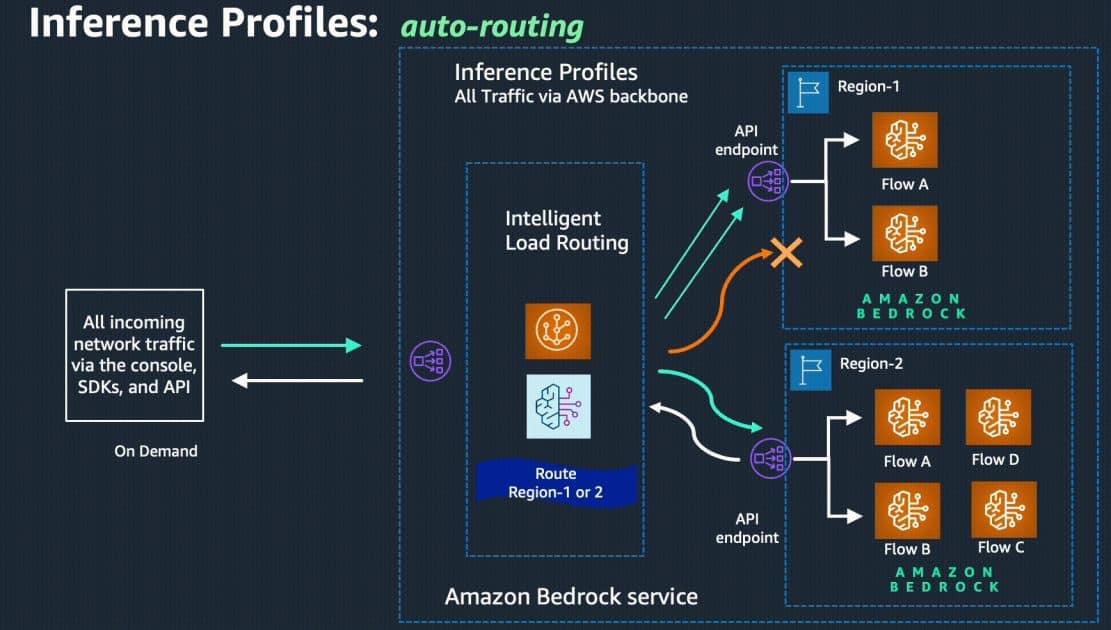
Hoy, nos complace anunciar la disponibilidad general de la inferencia entre regiones, una poderosa función que permite el enrutamiento automático de inferencias entre regiones para solicitudes que llegan a Amazon Bedrock. Esto ofrece a los desarrolladores que usan el modo de inferencia bajo demanda una solución perfecta para gestionar de manera óptima la disponibilidad, el rendimiento y la resiliencia mientras manejan picos de tráfico en aplicaciones impulsadas por Amazon Bedrock. Al optar por esta funcionalidad, los desarrolladores ya no tienen que dedicar tiempo y esfuerzo a predecir las fluctuaciones de la demanda. En su lugar, la inferencia entre regiones enruta dinámicamente el tráfico a través de múltiples regiones, asegurando una disponibilidad óptima para cada solicitud y un rendimiento más fluido durante los periodos de alta utilización. Además, esta capacidad prioriza la región fuente/principal del API de Amazon Bedrock cuando es posible, ayudando a minimizar la latencia y mejorar la capacidad de respuesta. Como resultado, los clientes pueden mejorar la fiabilidad, el rendimiento y la eficiencia de sus aplicaciones.
Profundicemos en esta funcionalidad:
Algunas características clave de la inferencia entre regiones incluyen:
– Utilización de la capacidad de múltiples regiones de AWS, permitiendo escalar cargas de trabajo de IA generativa con la demanda.
– Compatibilidad con la API existente de Amazon Bedrock.
– Sin costos adicionales de enrutamiento o transferencia de datos.
– Mayor resiliencia a los picos de tráfico.
– Posibilidad de elegir entre un rango de conjuntos de regiones preconfiguradas adaptadas a las necesidades del usuario.
Para empezar a usar esta funcionalidad, los usuarios deben aprovechar los perfiles de inferencia en Amazon Bedrock, que configuran diferentes ARNs de modelos de las respectivas regiones de AWS y los abstraen detrás de un identificador de modelo unificado. Simplemente utilizando este nuevo identificador de perfil de inferencia con la API de InvokeModel o Converse, los desarrolladores pueden aprovechar la inferencia entre regiones.
Para aquellos interesados en implementar esta nueva capacidad, es esencial evaluar cuidadosamente los requisitos de la aplicación, los patrones de tráfico y la infraestructura existente. Por ejemplo, debe analizarse las cargas de trabajo actuales y los patrones de tráfico, evaluar los beneficios potenciales de la inferencia entre regiones, planificar y ejecutar la migración de aplicaciones, y desarrollar nuevas aplicaciones teniendo en cuenta esta funcionalidad desde el inicio.
En conclusión, la inferencia entre regiones de Amazon Bedrock ofrece a los desarrolladores una potente herramienta para mejorar la fiabilidad, el rendimiento y la eficiencia de sus aplicaciones sin necesidad de esfuerzos significativos en la construcción de estructuras complejas de resiliencia. Esta funcionalidad ya está disponible en EE.UU. y la UE para los modelos soportados, marcando un importante avance en la capacidad de gestión de tráfico y disponibilidad para aplicaciones de IA generativa.