Compartir:
La velocidad y el costo continúan siendo retos importantes en el ámbito de la inteligencia artificial generativa, especialmente al trabajar con modelos de lenguaje de gran tamaño. Estos modelos, que son capaces de procesar enormes volúmenes de texto, operan de manera secuencial, prediciendo un token por vez. Esta característica puede introducir retrasos significativos que afectan adversamente la experiencia de usuario. Además, la creciente proliferación de aplicaciones basadas en inteligencia artificial ha generado un incremento notable en las solicitudes a estos modelos, lo que puede repercutir sustancialmente en los presupuestos de las organizaciones.
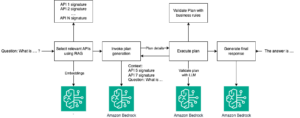
Para mitigar estos desafíos, se ha implementado recientemente una innovadora estrategia de optimización enfocada en las aplicaciones que utilizan LLM. En un mundo donde la eficiencia y la rentabilidad son cada vez más vitales, se ha desarrollado un esquema de almacenamiento en caché de lectura intermedia sin servidor, aprovechando patrones de datos recurrentes. Este sistema permite a los desarrolladores almacenar y recuperar respuestas similares eficientemente, mejorando así la eficiencia y los tiempos de respuesta en sus plataformas.
La solución integra Amazon OpenSearch Serverless y Amazon Bedrock, un servicio completamente administrado que provee modelos base de rendimiento sobresaliente, facilitando la construcción de aplicaciones de inteligencia artificial generativa bajo lineamientos de seguridad, privacidad y responsabilidad.
La caché actúa como un buffer intermediario que intercepta solicitudes en lenguaje natural antes de que alcancen el modelo primario, manteniendo consultas semánticamente semejantes. Esto asegura una rápida recuperación sin necesidad de someter la solicitud al modelo para una nueva generación, equilibrando entre incrementar los aciertos de caché y minimizar las colisiones.
Por ejemplo, en una empresa de viajes, un asistente de inteligencia artificial puede centrarse en un alto recuerdo, almacenando más respuestas y permitiendo cierta superposición de consultas. En cambio, en escenarios de servicio al cliente, podría requerirse una precisión rigurosa en cada petición, con el fin de reducir errores al mínimo.
El sistema opera generando incrustaciones vectoriales numéricas de las consultas de texto, transformándolas en vectores para su almacenamiento. La selección de modelos de incrustación gestionados desde Amazon Bedrock posibilita el establecimiento de bases de datos de vectores con OpenSearch Serverless, consolidando un sistema de caché robusto y sólido.
Este enfoque no solo optimiza los tiempos de respuesta; también es altamente rentable, ya que los modelos de incrustación suelen ser más asequibles que los modelos de generación, ofreciendo una solución costo-efectiva para diversas aplicaciones.
La introducción de esta tecnología es una significativa evolución no solo en términos de eficiencia operativa, sino también en la experiencia del usuario, permitiendo ajustar los umbrales de similitud para un balance óptimo entre aciertos y colisiones dentro de la caché.