
Compartir:
En los últimos meses, el avance en el desarrollo de modelos de lenguaje de gran escala ha llevado a una adopción masiva de asistentes virtuales en diversas compañías. Estos asistentes, basados en el modelo de generación aumentada por recuperación, utilizan modelos de lenguaje sumamente sofisticados para consultar documentación específica de la empresa y responder preguntas relevantes a situaciones particulares. Esta tendencia ha sido impulsada por el creciente interés en mejorar tanto la atención al cliente como la eficiencia interna de las organizaciones.
Los modelos fundacionales multimodales han emergido como una innovación significativa, ofreciendo la capacidad de interpretar y generar texto a partir de imágenes, conectando así la información visual con el lenguaje natural. Sin embargo, a pesar de su utilidad, estos modelos enfrentan el desafío de ser limitados a los datos con los que fueron entrenados inicialmente.
En este escenario, Amazon Web Services (AWS) ha demostrado cómo se puede crear un asistente de chat multimodal mediante el uso de Amazon Bedrock, una herramienta diseñada para permitir a los usuarios enviar imágenes y preguntas, obteniendo respuestas basadas en un conjunto específico de documentos de la empresa. Esta tecnología puede ser particularmente útil en la industria minorista para potenciar la venta de productos o en la fabricación para facilitar el mantenimiento de maquinaria.
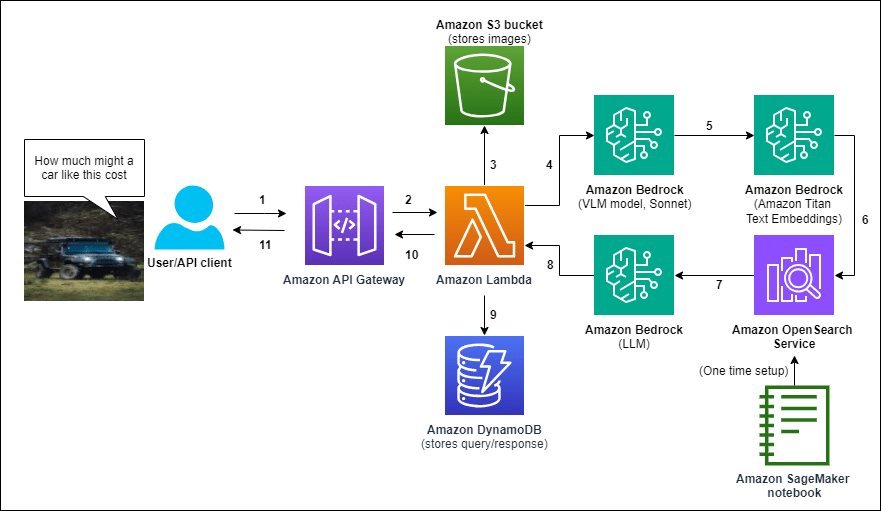
AWS ha desarrollado una solución que comienza con la creación de una base de datos vectorial de documentos relevantes utilizando Amazon OpenSearch Service. El lanzamiento del asistente de chat se realiza mediante una plantilla de AWS CloudFormation, asegurando una implementación estructurada y eficiente.
El funcionamiento del sistema sigue una serie de pasos definidos: un usuario sube una imagen y plantea una pregunta, que son procesadas a través de Amazon API Gateway hacia una función de AWS Lambda. Esta función, que actúa como el núcleo del sistema, almacena la imagen en Amazon S3 para análisis futuros. Luego, coordina llamadas a modelos de Amazon Bedrock para generar una descripción textual de la imagen, convertir la consulta y la descripción en una representación vectorial, recuperar información relevante de OpenSearch y formular una respuesta basada en los documentos obtenidos. Tanto la consulta del usuario como la respuesta generada se almacenan en Amazon DynamoDB, asociadas con el ID de la imagen en S3.
Esta propuesta presenta una oportunidad importante para sectores que requieren respuestas específicas basadas en sus propios conjuntos de datos con entradas multimodales. Un ejemplo destacado es su aplicación en un mercado de automóviles, donde los usuarios pueden cargar una imagen de un vehículo, hacer preguntas y recibir respuestas basadas en una base de datos exclusiva de listados de autos, demostrando su versatilidad y utilidad en diversos ámbitos.
Una de las ventajas más destacables de esta solución es su habilidad para ofrecer respuestas precisas y contextualizadas, fundamentadas en datos empresariales específicos, lo que no solo mejora la experiencia del usuario, sino que también incrementa la eficiencia operativa. Adicionalmente, la personalización y escalabilidad del sistema permiten a las empresas adaptar el asistente a necesidades particulares, explorando nuevos horizontes en la interacción entre humano y máquina.









