Compartir:
El avance imparable de la inteligencia artificial está llevando a las organizaciones a replantearse el uso de datos sintéticos como una herramienta crucial para fomentar la innovación. En un mundo donde las regulaciones de privacidad son cada vez más estrictas, el uso cuidadoso de los datos se torna fundamental. Los datos sintéticos se presentan como la solución potencial para aprovechar el poder de la inteligencia artificial sin comprometer la seguridad de la información sensible.
Las empresas enfrentan diversos desafíos al intentar utilizar datos reales: la exposición a riesgos legales y de reputación debido a la posibilidad de que se descubran correlaciones ocultas, incluso después de una anonimización exhaustiva. A estos retos se suma la falta de conjuntos de datos de alta calidad y diversidad, esenciales para el desarrollo de productos, pruebas de software y el entrenamiento de modelos de inteligencia artificial. Esta limitación podría frenar los avances en varios sectores, ralentizando los ciclos de innovación.
El uso de datos sintéticos, que reproducen las propiedades estadísticas de los datos reales pero son completamente ficticios, permite a las empresas entrenar sus modelos de IA y desarrollar aplicaciones sin exponerse a los peligros inherentes al manejo de información sensible. De esta manera, logran un equilibrio entre la protección de la privacidad y el aprovechamiento de los datos para la toma de decisiones.
No obstante, la creación de datos sintéticos de calidad no es un proceso exento de complicaciones. Es necesario gestionar aspectos críticos como la calidad de los datos, la eliminación de sesgos, y el balance entre privacidad y utilidad. Además, existe el riesgo de que estos datos no reflejen con precisión la variabilidad del mundo real, lo que puede generar brechas en la aplicación práctica de los modelos entrenados con ellos.
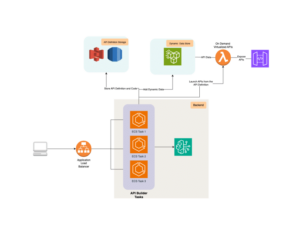
Amazon Bedrock ha emergido como una herramienta pionera en la generación de datos sintéticos, ofreciendo a las organizaciones la posibilidad de implementar soluciones de inteligencia artificial generativa bajo un marco de seguridad y privacidad robusto. Bedrock facilita el diseño de datos sintéticos realistas y fiables, imitando las estructuras y patrones de los datos reales, mientras se asegura un anonimato total.
Para generar estos conjuntos de datos sintéticos, es crucial llevar a cabo un proceso estructurado que incluye definir reglas de validación precisas, generar código para crear subconjuntos de datos y finalmente, integrarlos en conjuntos más amplios. Sin embargo, las preocupaciones de privacidad persisten, lo que hace imprescindible la incorporación de técnicas de privacidad diferencial que añadan ruido intencional al proceso de generación de datos para impedir inferencias no deseadas.
Combinando los modelos de lenguaje proporcionados por Amazon Bedrock con el conocimiento específico de cada industria, las organizaciones pueden desarrollar métodos seguros y flexibles para crear datos de prueba realistas. De este modo, no solo se enfrentan los desafíos asociados al manejo de datos, sino que también se fomenta un camino hacia la innovación responsable y la fortificación de las prácticas de desarrollo y prueba en el mundo empresarial moderno.