Compartir:
La integración de avanzadas capacidades de inteligencia artificial en el ámbito empresarial continúa creciendo a pasos agigantados, requiriendo cada vez más soluciones escalables y eficientes para el entrenamiento de modelos. En este contexto, el Framework NVIDIA NeMo se posiciona como una herramienta esencial para desarrollar, personalizar y desplegar modelos de IA a gran escala. Al mismo tiempo, Amazon SageMaker HyperPod ofrece la infraestructura distribuida necesaria, permitiendo gestionar trabajos complejos en múltiples GPU y nodos de manera efectiva.
Recientemente, se ha dado un paso significativo al integrar NeMo 2.0 con SageMaker HyperPod, posibilitando un entrenamiento eficiente de grandes modelos de lenguaje. Este avance incluye una guía detallada que permite configurar y ejecutar de manera efectiva los trabajos de NeMo dentro de un clúster de SageMaker HyperPod.
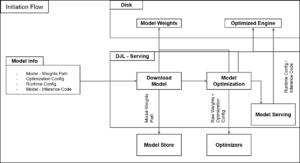
El NVIDIA NeMo Framework sobresale por ofrecer una solución completa que abarca todo el ciclo de vida de desarrollo de modelos de IA. Incluye herramientas de desarrollo avanzadas, opciones de personalización y una infraestructura optimizada, lo que reduce la complejidad y los costos asociados al desarrollo de inteligencia artificial generativa. La versión 2.0 del marco, desarrollada en Python, garantiza una integración sencilla en los flujos de trabajo ya existentes para los desarrolladores.
Entre las características destacadas de NeMo se encuentran la curación de datos, el entrenamiento y la personalización de modelos. Los desarrolladores también tienen a su disposición herramientas para la alineación de modelos, como NeMo Curator y NeMo Aligner. Estas herramientas son fundamentales para gestionar eficientemente el rendimiento de los modelos generativos, garantizando modelos de lenguaje más seguros y útiles.
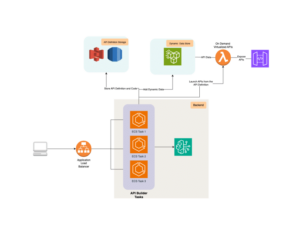
Para implantar esta solución, es necesario seguir una serie de pasos que incluyen la configuración de los requisitos previos de SageMaker HyperPod, la puesta en marcha del clúster y la configuración del entorno de NeMo. Además, es esencial crear un contenedor personalizado que integre el NeMo Framework junto con sus dependencias.
Con el clúster operativo, se puede iniciar el entrenamiento del modelo utilizando NeMo-Run, lo que optimiza la utilización de los recursos computacionales disponibles. Esta metodología no solo mejora la eficiencia, sino que también permite ejecutar modelos de lenguaje de gran tamaño, como LLaMA, de manera más accesible y efectiva.
En resumen, la combinación del NVIDIA NeMo Framework 2.0 con Amazon SageMaker HyperPod ofrece un enfoque innovador para el entrenamiento de modelos de inteligencia artificial generativa, simplificando el uso de la computación distribuida gracias a un proceso de configuración más accesible para las empresas.