Compartir:
Amazon ha demostrado nuevamente su liderazgo en el ámbito del aprendizaje automático con su herramienta Amazon SageMaker Pipelines, que se ha consolidado como un recurso fundamental para científicos de datos y desarrolladores en todo el mundo. Esta plataforma facilita la automatización y optimización de flujos de trabajo de aprendizaje automático, liberando a los equipos de la gestión de infraestructuras, y permisiblemente focalizándolos en el desarrollo y rápida experimentación de modelos.
Con un SDK de Python, SageMaker Pipelines permite la orquestación de flujos de trabajo sofisticados y su visualización mediante SageMaker Studio. Esto no solo mejora las actividades de preparación y la ingeniería de características de datos, sino que también promueve la automatización en el entrenamiento y despliegue de modelos. Al integrarse con Amazon SageMaker Automatic Model Tuning, la plataforma ajusta automáticamente los valores de hiperparámetros para optimizar el rendimiento de los modelos según métricas predefinidas por los usuarios.
El interés creciente de la comunidad del aprendizaje automático en los modelos de conjuntos, que logran mayor precisión al combinar resultados de múltiples modelos, ha encontrado un gran aliado en Amazon SageMaker Pipelines. Los desarrolladores pueden implementar rápidamente un proceso de aprendizaje automático integral para estos modelos, asegurando tanto la precisión como la eficiencia.
Un caso ejemplar reciente mostró el uso de modelos de conjuntos implementados a través de SageMaker Pipelines en el ámbito de ventas y oportunidades en Salesforce. Un modelo de aprendizaje no supervisado fue utilizado para identificar automáticamente casos de uso específicos de cada oportunidad. Este proceso de identificación es crítico ya que difiere por industria y afecta la distribución de ingresos anualizados. La aproximación abordó la identificación de temas mediante modelos como LSA, LDA y BERTopic, siendo este último el más efectivo al superar limitaciones comunes de otros modelos.
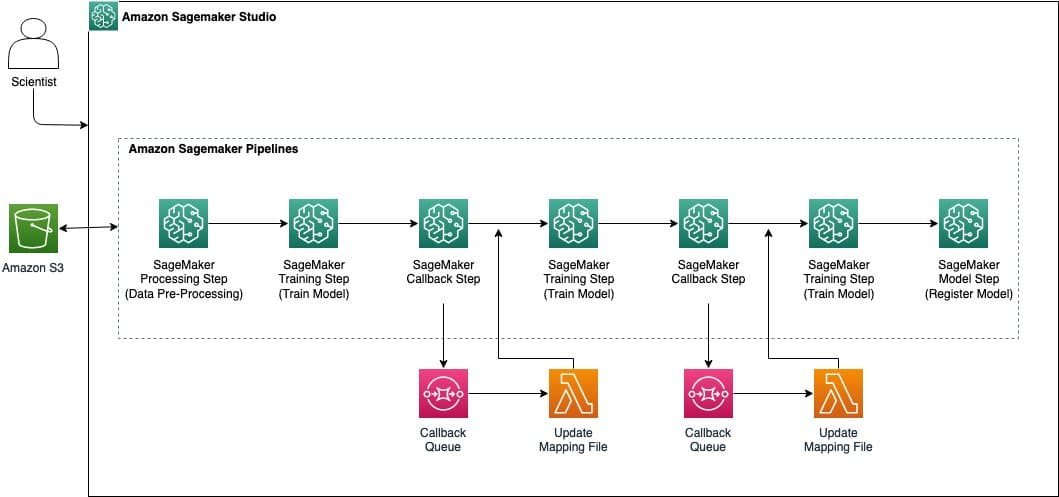
La solución implementada incluyó tres modelos secuenciales de BERTopic de manera jerárquica para lograr la agrupación final. Soportado por técnicas como UMAP para reducción de dimensiones y BIRCH para clustering, este enfoque garantiza resultados precisos y representativos.
Sin embargo, el diseñar esta estrategia no fue tarea sencilla. Desde el preprocesamiento eficaz de datos, vital para el rendimiento del modelo, hasta la necesidad de un entorno computacional altamente escalable que gestione millones de filas, la adaptabilidad del pipeline resultó esencial para su éxito.
En el aspecto arquitectónico, SageMaker Studio actúa como el punto de acceso, proporcionando un entorno colaborativo y eficiente para la construcción, entrenamiento y despliegue de modelos de aprendizaje automático a gran escala. A través de pasos de procesamiento, entrenamiento, callback y modelado, se coordina el flujo automatizado de trabajo de manera obtenida.
Este enfoque meticuloso para la implementación de modelos de aprendizaje automático ilustra el poder de Amazon SageMaker Pipelines, permitiendo a las empresas superarse frente a los desafíos de la automatización y escalabilidad en sus proyectos de inteligencia artificial y aprendizaje automático.