Compartir:
Los agentes de inteligencia artificial están desempeñando un papel cada vez más relevante en el ámbito de la atención al cliente, apoyando la automatización de tareas complejas, mejorando la toma de decisiones y optimizando operaciones. Sin embargo, su exitoso funcionamiento en sistemas productivos requiere la implementación de pipelines de evaluación escalables y eficientes. Esta evaluación meticulosa permite medir su desempeño en funciones específicas, proporcionando datos esenciales para mejorar la seguridad, control, confianza, transparencia y rendimiento de estos sistemas.
Amazon Bedrock Agents utiliza la lógica de modelos de base disponibles en esta plataforma, junto con APIs y datos, para desglosar solicitudes, recopilar información relevante y ejecutar tareas eficientemente. Este sistema facilita que los equipos humanos se concentren en tareas de mayor valor agregado, permitiendo la automatización de procesos que demandan múltiples pasos.
La herramienta Ragas, una librería de código abierto, ha surgido como un recurso clave para evaluar aplicaciones de modelos de lenguaje grande, incluidas las de generación aumentada por recuperación (RAG). Recientemente, se ha empleado en estudios para valorar la capacidad RAG de Amazon Bedrock Agents.
Para evaluar la calidad de las salidas generadas por la IA, se ha utilizado la metodología LLM-as-a-judge, donde modelos de lenguaje juzgan la efectividad de las conversiones de texto a SQL y el razonamiento en cadena. Adicionalmente, Langfuse, otra plataforma de código abierto, proporciona herramientas como trazas y métricas para depurar y mejorar estas aplicaciones.
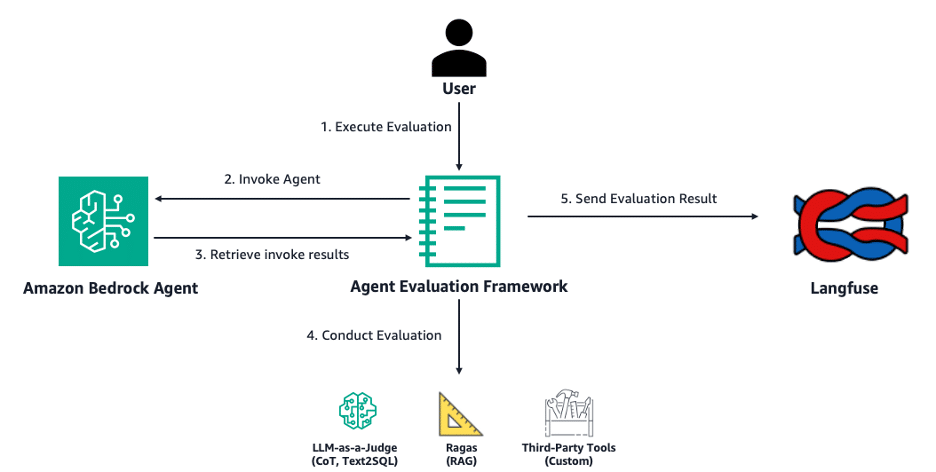
Un reciente avance ha sido la presentación de un marco de evaluación de agentes Bedrock de código abierto, habilitado para juzgar el rendimiento de agentes en tareas como RAG, conversión de texto a SQL y el uso de herramientas personalizadas, además de permitir una visualización detallada de resultados en Langfuse. No obstante, los desarrolladores enfrentan desafíos, como la complejidad de realizar evaluaciones completas con métricas específicas para estos agentes y la gestión de experimentos dada la multiplicidad de configuraciones.
El marco Open Source Bedrock Agent Evaluation ha simplificado este proceso al permitir la especificación de un ID de agente y la ejecución de trabajos de evaluación directamente en Amazon Bedrock, generando trazas que se analizan y evalúan, con resultados integrados en Langfuse para métricas agregadas.
La evaluación de estas tecnologías es de especial importancia en la investigación farmacéutica, donde agentes diseñados colaboran y analizan datos sobre biomarcadores, facilitando el hallazgo de información clave en la investigación médica. La integración y evaluación de las capacidades de estos agentes es crucial para asegurar tanto su rendimiento como la confianza y seguridad en entornos críticos.