Compartir:
En un esfuerzo por mejorar la precisión y la confiabilidad de las aplicaciones de inteligencia artificial generativa en el ámbito de la salud, se ha desarrollado un nuevo enfoque de evaluación utilizando modelos de lenguaje grande (LLM) en combinación con Amazon Bedrock. Este avance surge en un momento en que las herramientas de inteligencia artificial están cada vez más integradas en entornos clínicos, requiriendo evaluaciones rigurosas para garantizar que la información generada sea tanto precisa como clínicamente relevante.
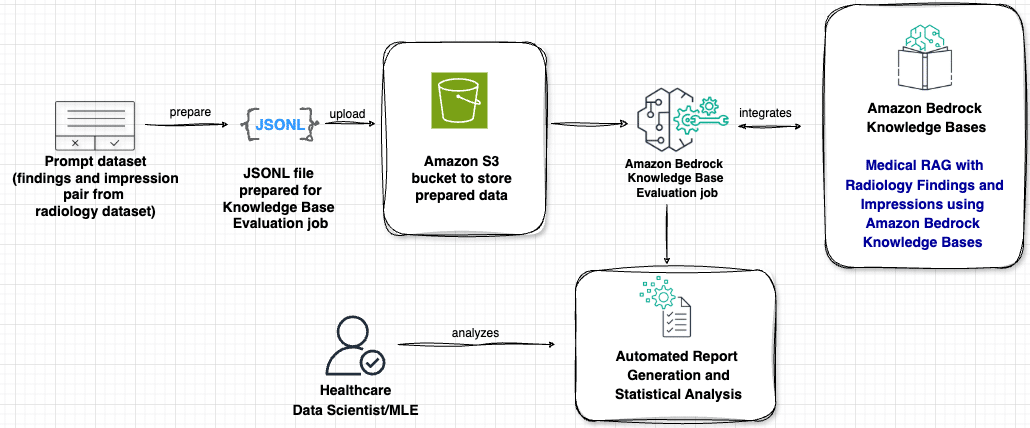
En publicaciones anteriores, se exploraron distintas técnicas como el ajuste fino de modelos de lenguaje grande, la ingeniería de prompts y la Generación Aumentada por Recuperación (RAG). Estas técnicas utilizan Amazon Bedrock para crear impresiones a partir de los hallazgos en informes de radiología mediante IA generativa. La combinación de modelos de lenguaje con bases de conocimiento externas a través de RAG ha mostrado mejoras significativas en la precisión, reduciendo ‘alucinaciones’ y elevando el nivel de respuesta clínicamente adecuada.
Sin embargo, evaluar la efectividad de estos sistemas RAG en aplicaciones médicas ha sido un desafío constante, principalmente porque las métricas existentes, como las puntuaciones ROUGE, no podían medir adecuadamente si el conocimiento médico recuperado se integraba correctamente ni si mantenía la precisión clínica necesaria.
Ahora, en una tercera fase, se ha introducido un sistema de evaluación que posiciona al modelo LLM como juez, junto con Amazon Bedrock. Este marco innovador está diseñado para enfrentar los desafíos únicos que presentan los sistemas RAG en el sector salud, asegurando que tanto la calidad del contenido generado como la precisión del conocimiento médico recuperado satisfacen los estándares clínicos más estrictos.
La utilización del nuevo método de evaluación permite no solo analizar cómo estos sistemas recuperan y emplean información médica para generar respuestas contextualmente adecuadas, sino también establecer nuevos puntos de referencia para la evaluación médica de RAG. En las pruebas realizadas, se comparó el rendimiento de diferentes modelos generadores, como Claude de Anthropic y Nova de Amazon, y se incorporó la función de evaluación RAG, facilitando así la optimización de parámetros en las bases de conocimiento.
Este avance ofrece herramientas prácticas a los profesionales del sector salud, permitiéndoles desarrollar aplicaciones de inteligencia artificial que puedan ser implementadas con confianza en entornos clínicos, al tiempo que garantiza que las aplicaciones RAG continúen alineándose con los estándares de precisión y claridad exigidos en el ámbito médico.