Compartir:
La evaluación de modelos de lenguaje a gran escala (LLMs) se ha convertido en una tarea fundamental en la era digital, donde estos sistemas tienen un impacto significativo en diversas áreas de la sociedad, como la salud, la educación y la toma de decisiones. Los LLMs requieren rigurosas pruebas para mejorar la comprensión de sus capacidades y limitaciones, así como para identificar posibles sesgos. Estos procesos de evaluación permiten no solo asegurar la efectividad de los modelos, sino también garantizar que se utilicen de manera correcta y segura. La calidad de las plantillas de instrucciones y de los datos de entrada es esencial para todo el ecosistema de aplicaciones que dependen de ellos, subrayando la importancia de un enfoque holístico en su desarrollo y ejecución.
Para cualquier desarrollador involucrado en proyectos de inteligencia artificial que utilicen LLMs, asumir un enfoque exhaustivo en la evaluación es primordial. Estas evaluaciones permiten determinar si un modelo es adecuado para ciertas tareas, dado que el rendimiento puede variar según el contexto. También son cruciales durante las fases de desarrollo, ya que aseguran la alta calidad de las soluciones mediante la validación de plantillas de entrada y evaluaciones de desempeño antes de implementar un modelo a gran escala. Asimismo, estos procesos de evaluación ayudan a las organizaciones a mantenerse actualizadas con los avances tecnológicos, permitiéndoles tomar decisiones estratégicas sobre la actualización de modelos y el mantenimiento de la competitividad en el mercado. Invertir en un marco de evaluación sólido también es vital para mitigar preocupaciones sobre la privacidad de los datos, el cumplimiento normativo y el riesgo reputacional asociado a los resultados incorrectos o poco éticos generados por los LLMs.
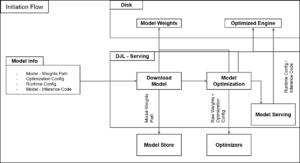
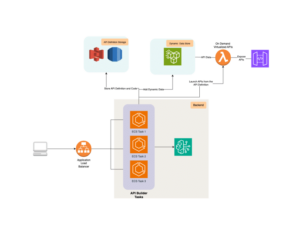
Además, el seguimiento preciso de modelos, plantillas de instrucciones y conjuntos de datos es clave para el desarrollo de aplicaciones de inteligencia artificial generativa. Esta práctica de documentación rigurosa permite a los desarrolladores e investigadores mantener consistencia, reproducir resultados y optimizar continuamente sus modelos. Documentar cada detalle, desde versiones de modelos hasta parámetros de ajuste y enfoques de ingeniería de instrucciones, es invaluable para comprender los elementos que influyen en el rendimiento del sistema. También facilita la detección de sesgos potenciales inherentes al conjunto de datos empleado. En este sentido, el uso de herramientas como FMEval y Amazon SageMaker resulta un avance significativo. FMEval, una biblioteca de código abierto, se especializa en evaluar distintos aspectos de los LLMs, incluyendo precisión y toxicidad, mientras que SageMaker proporciona un entorno estructurado para llevar a cabo investigaciones eficientes y bien documentadas. Al integrar estas herramientas, las empresas pueden construir flujos de trabajo robustos que optimicen el proceso de evaluación de la inteligencia artificial generativa, fortaleciendo la toma de decisiones informadas y eficientes en el mundo de los modelos de lenguaje grandes.