
Compartir:
En un mundo cada vez más dependiente de los datos para el desarrollo de aplicaciones y negocios, la precisión y fiabilidad de esta información se han vuelto esenciales. Aquí es donde entra en juego la inteligencia artificial generativa, especialmente a través de los grandes modelos de lenguaje (LLMs). Estos modelos, robustos y bien entrenados, han comenzado a ofrecer una solución innovadora a la creciente demanda de datos fidedignos y variados en distintos formatos y dominios.
El sector financiero es uno de los más beneficiados por estas tecnologías avanzadas. Instituciones como el ficticio Banco ABC han adoptado modelos de aprendizaje automático para gestionar el riesgo asociado a los derivados extrabursátiles (OTC). Estos derivados son contratos financieros complejos y personalizados, como swaps y opciones, donde la gestión del riesgo de contraparte es crítica. Este tipo de riesgo implica una distribución equitativa de responsabilidades y riesgos financieros entre las entidades involucradas.
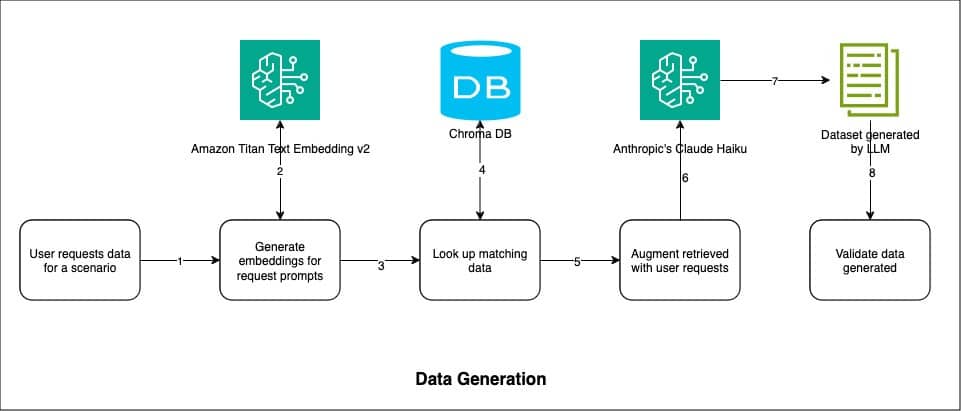
Sin embargo, crear modelos precisos de evaluación de riesgo no es una tarea libre de desafíos. Pese a la disponibilidad de grandes volúmenes de datos, estos pueden contener sesgos o carecer de la diversidad necesaria para que el modelo sea efectivo. Para contrarrestar estos problemas, se ha propuesto una innovadora aproximación basada en inteligencia artificial generativa, concretamente utilizando la técnica de Generación Aumentada por Recuperación (RAG). Este método mejora los LLMs añadiendo información adicional proveniente de fuentes externas a las que el modelo original no tuvo acceso durante su entrenamiento.
La implementación de este enfoque se divide en tres etapas claves: indexación, generación y validación de datos. En la primera, los datos de riesgo de contraparte se procesan y almacenan en bases de datos vectoriales, lo que facilita búsquedas eficientes por similitud. La siguiente fase consiste en la generación de datos, donde se busca información coincidente en la base de datos procesada y se alimenta a un modelo de IA. En este caso, la elección recae sobre Claude Haiku de Anthropic, un modelo famoso por su rapidez y precisión en la generación de datos.
Validar los datos sintéticos generados es un paso crucial para garantizar su calidad y fiabilidad. Herramientas estadísticas avanzadas, como gráficos de cuantiles y mapas de calor de correlación, se emplean para asegurar que los datos generados mantengan propiedades similares a los reales, evitando patrones artificiales o sesgos que puedan influir negativamente en las decisiones empresariales.
Además, es imprescindible que las instituciones financieras se adhieran a prácticas responsables en el uso de la inteligencia artificial. La protección de la privacidad es fundamental, garantizando que no se utilicen datos personales sin autorización adecuada. Al conjugar la innovación tecnológica con exigencias éticas, las organizaciones pueden aprovechar al máximo los beneficios de la inteligencia artificial, asegurando la confianza de sus clientes.
En conclusión, la generación de datos sintéticos mediante modelos generativos se erige como una solución efectiva para crear conjuntos de datos fiables en el sector financiero. Este enfoque no solo mejora la capacidad de evaluar riesgos de contraparte, sino que también facilita decisiones más informadas y seguras en operaciones complejas como las de transacciones OTC.









