Compartir:
Con la creciente prevalencia de aplicaciones de inteligencia artificial generativa (IA), mantener principios responsables de IA se vuelve esencial. Sin las salvaguardas adecuadas, los modelos de lenguaje grandes (LLMs) pueden generar contenido dañino, sesgado o inapropiado, lo cual representa riesgos para individuos y organizaciones. La aplicación de guardrails ayuda a mitigar estos riesgos al imponer políticas y directrices que se alinean con principios éticos y requisitos legales. Los Guardrails para Amazon Bedrock evalúan entradas de usuario y respuestas de modelos basados en políticas específicas de uso, proporcionando una capa adicional de salvaguardas sin importar el modelo subyacente. Además, estos guardrails pueden aplicarse a todos los LLM en Amazon Bedrock, incluyendo modelos afinados y aplicaciones de IA generativa fuera de esta plataforma.
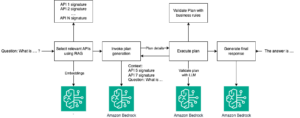
El nuevo API ApplyGuardrail permite evaluar cualquier texto usando guardrails preconfigurados en Amazon Bedrock, sin invocar los FMs. Esto se demuestra con inputs de largo contexto y salidas en streaming. La API, fácil de usar y desacoplada de los FMs, puede integrarse en cualquier flujo de aplicación para validar datos antes de procesar o servir resultados a los usuarios, lo que es útil en aplicaciones como la Generación Aumentada por Recuperación (RAG).
La API ofrece funciones clave como facilidad de uso y desacoplamiento de los FMs, permitiendo su uso con modelos alojados en Amazon SageMaker o incluso autohospedados. Los resultados de la evaluación de ApplyGuardrail pueden diseñar la experiencia en aplicaciones de IA generativa, asegurando la adherencia a políticas y directrices definidas.
Una de las principales ventajas de la API ApplyGuardrail es su capacidad para abordar desafíos de salida en streaming, donde el texto es generado token por token. Para aplicar guardrails en tiempo real, se requiere una estrategia que combine la evaluación por lotes y en tiempo real, permitiendo decisiones rápidas mientras se mantiene la coherencia del texto generado.
En términos de entradas de largo contexto, como en aplicaciones RAG, la estrategia implica dividir el texto en lotes manejables y procesarlos secuencialmente para evitar límites de tasa. Esto asegura que se puedan mantener las políticas de salvaguarda mientras se maneja información extensa y completa.
Se recomienda seguir prácticas óptimas, como desarrollar estrategias de fragmentación cuidadosa, procesamiento asíncrono y mecanismos de reserva para garantizar la eficiencia en la moderación del contenido. Además, auditar regularmente la implementación de los guardrails y ajustar según sea necesario para mantener la efectividad y alineación con las necesidades de moderación de contenido.
La implementación adecuada de los guardrails permite una moderación de contenido a escala, políticas personalizables, moderación en tiempo real, integración con cualquier LLM, y una solución rentable basada en un modelo de precios por uso. Al seguir las mejores prácticas y estrategias detalladas, los desarrolladores pueden asegurar que sus aplicaciones de IA generativa sean seguras y responsables, además de estar en conformidad con los estándares de moderación de contenido.
Con este enfoque, Amazon sigue fortaleciendo el uso de IA responsable a través de herramientas como la API ApplyGuardrail, facilitando la integración en aplicaciones de IA generativa para moderación de contenido efectiva y en tiempo real.