Compartir:
El ajuste fino de modelos de lenguaje grandes (LLM) preentrenados se ha convertido en una herramienta crucial para personalizar y optimizar el rendimiento de estos sistemas en tareas específicas. Este proceso continuo asegura que los modelos adapten su precisión y efectividad ante cambios en los datos y eviten una posible degradación en su desempeño con el tiempo. Esta fine-tuning continuo no solo adapta el modelo a aplicaciones del mundo real, sino que también integra retroalimentación humana para mejorar consistentemente su output.
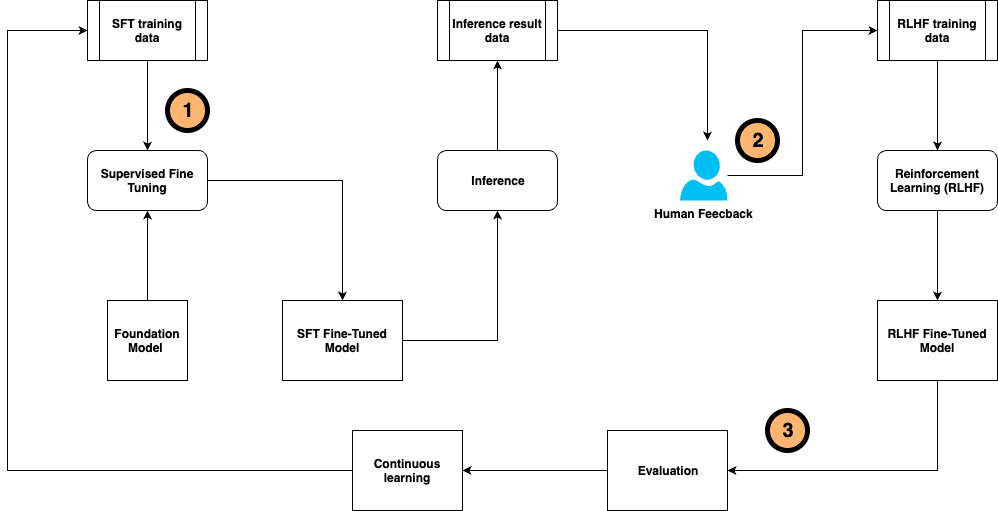
Dentro de las técnicas más relevantes en este ámbito, se destaca el ajuste fino supervisado (SFT) y la afinación de instrucciones basadas en conjuntos de datos anotados por humanos. La retroalimentación generada por los usuarios y el aprendizaje por refuerzo basado en esta información (RLHF) permiten guiar las respuestas de los LLM, alineándolas con las expectativas humanas.
Sin embargo, alcanzar resultados precisos y responsables en estos modelos requiere mucho esfuerzo, especialmente en la anotación manual de grandes volúmenes de datos y la obtención de comentarios de los usuarios. Este proceso de ajuste fino debe coordinar la generación de datos, el entrenamiento del modelo, la recolección de retroalimentación y la alineación con preferencias humanas, tareas que son intensivas tanto en recursos como en tiempo.
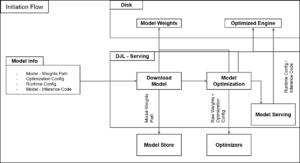
Con el objetivo de simplificar este desafío, se ha desarrollado un innovador marco de ajuste fino auto-instruido continuo. Este sistema optimiza el proceso de ajuste fino al unificar la generación y anotación de datos de entrenamiento, además del entrenamiento y evaluación del modelo y la recolección de retroalimentación humana. Se plantea como un sistema de inteligencia artificial compuesto que busca mejorar la eficiencia y versatilidad del flujo de trabajo.
El marco propuesto personaliza el modelo base mediante muestras de entrenamiento etiquetadas por humanos y retroalimentaciones obtenidas después de la inferencia del modelo. Este proceso es continuo, lo que permite adaptarse a entornos cambiantes.
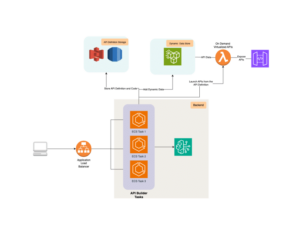
Además, para que esta arquitectura sea efectiva, se ha desarrollado un sistema de IA compuesto que resuelve las complicaciones de los modelos monolíticos tradicionales. La interacción entre múltiples componentes, como modelos, recuperadores y herramientas externas, ofrece soluciones más sofisticadas y eficientes.
Para construir y optimizar estos sistemas, se introduce DSPy, un marco de programación de Python de código abierto. Este framework facilita a los desarrolladores la creación de aplicaciones LLM a través de una programación modular y declarativa, optimizando resultados y mejorando la experiencia del usuario en aplicaciones de inteligencia artificial.
En resumen, este sistema de ajuste fino continuo y auto-instruido no solo incrementa la precisión y rendimiento de los modelos de lenguaje, sino que también establece un marco que maximiza la reutilización y adaptabilidad frente a los constantes cambios de datos y necesidades del usuario.