Compartir:
Amazon ha presentado Amazon Bedrock Model Distillation, una innovadora solución que responde al desafío que enfrentan muchas organizaciones al implementar inteligencia artificial generativa: cómo lograr un alto rendimiento mientras se reducen costos y tiempos de latencia. Esta técnica permite transferir el conocimiento de modelos de base más grandes y avanzados a modelos más pequeños y eficientes, creando modelos especializados para tareas específicas. La tecnología se apoya en la familia de modelos Llama de Meta y emplea métodos avanzados de aumento de datos y mejoras de rendimiento.
Una característica esencial de esta herramienta es la capacidad de llamada a funciones, que permite a los modelos interactuar con herramientas externas, bases de datos y APIs, determinando con precisión cuándo y cómo invocar funciones específicas. Aunque los modelos más grandes suelen ser más efectivos en identificar funciones adecuadas, su uso conlleva mayores costos y tiempos de respuesta. Con Amazon Bedrock Model Distillation, ahora modelos más pequeños pueden igualar la precisión de llamada a funciones ofreciendo tiempos de respuesta más rápidos y reduciendo significativamente los costos operativos.
El valor de esta propuesta es considerable: las organizaciones pueden desplegar agentes de IA que mantienen una alta precisión en la selección de herramientas y en la construcción de parámetros, mientras disfrutan de menores tamaños de modelo y mayor rendimiento. Esto amplía la accesibilidad económica de arquitecturas complejas a una variedad más amplia de aplicaciones.
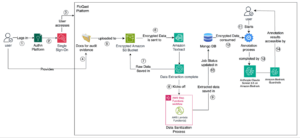
Para implementar eficazmente Amazon Bedrock Model Distillation, se deben cumplir ciertos requisitos, como tener una cuenta activa de AWS, utilizar los modelos adecuados de maestro y estudiante, contar con un bucket de S3 para el almacenamiento de datos, y disponer de los permisos de IAM necesarios.
La preparación adecuada de datos es crucial para el éxito en la destilación de funciones. Amazon Bedrock ofrece dos métodos principales para preparar datos de entrenamiento: subir archivos JSONL a Amazon S3 o emplear registros de invocación históricos. Es crucial que las especificaciones de herramientas estén bien formateadas para permitir una destilación exitosa.
Las mejoras que presenta Amazon Bedrock Model Distillation incluyen un soporte más amplio de modelos y la integración de tecnología avanzada de síntesis de datos, que genera ejemplos de entrenamiento adicionales para mejorar la capacidad del modelo. Además, se ha mejorado la transparencia del proceso de entrenamiento, permitiendo a los usuarios visualizar el entrenamiento de sus modelos y recibir informes sobre los prompts aceptados y rechazados.
Las evaluaciones demuestran que los modelos destilados para llamadas a funciones pueden lograr una precisión similar a modelos significativamente más grandes, con tiempos de inferencia más rápidos y costos operativos reducidos. Esto facilita una implementación escalable de agentes de IA capaces de interactuar con herramientas y sistemas externos en diversas aplicaciones empresariales. La combinación de precisión, velocidad y eficiencia de costos emerge como un factor clave para los desarrolladores que buscan maximizar el potencial de la inteligencia generativa en sus aplicaciones.