
Compartir:
En la actualidad, las organizaciones enfrentan el desafío de extraer información estructurada de documentos PDF no estructurados, los cuales pueden contener una variedad de elementos como imágenes, tablas, encabezados y texto en diversos formatos, lo que dificulta el análisis eficiente de los datos.
Además, el desempeño de los chatbots y otras aplicaciones de procesamiento de lenguaje natural (NLP) depende en gran medida de la estrategia de división de texto utilizada. Una división inapropiada puede llevar a la pérdida de contexto, resultando en respuestas imprecisas o incoherentes. La eficiencia de los modelos de lenguaje también se ve afectada por el tamaño de los fragmentos, ofreciendo información más detallada en fragmentos más pequeños, pero con dificultades para generalizar, mientras que fragmentos más grandes pueden omitir detalles importantes.
En este contexto, Accenture ha aprovechado las capacidades de personalización de Knowledge Bases para Amazon Bedrock, integrando un flujo de procesamiento de datos y lógica personalizada para crear un mecanismo de división de texto que mejora el desempeño de la Generación Aumentada por Recuperación (RAG) y libera el potencial de los datos en PDF.
El equipo de Accenture creó una base de conocimiento con los resultados financieros de la compañía para cada trimestre desde 2020 hasta 2024. Este documento incluía imágenes, tablas, texto en diferentes formatos y otros elementos ruidosos. El objetivo era extraer información detallada de las tablas y preservar las capacidades de generalización de los modelos de fundación para responder a preguntas generales sobre los resultados financieros.
Después de varias pruebas, se descubrió que el mecanismo de búsqueda no lograba recuperar correctamente la información para los años y trimestres especificados en las consultas. Un ejemplo mostró que, al buscar información del primer trimestre de 2023, el sistema devolvió datos del primer trimestre de 2020. Al identificar problemas en la selección de fragmentos correctos, Accenture decidió cambiar la estrategia de división de texto utilizando las nuevas características de Amazon Bedrock.
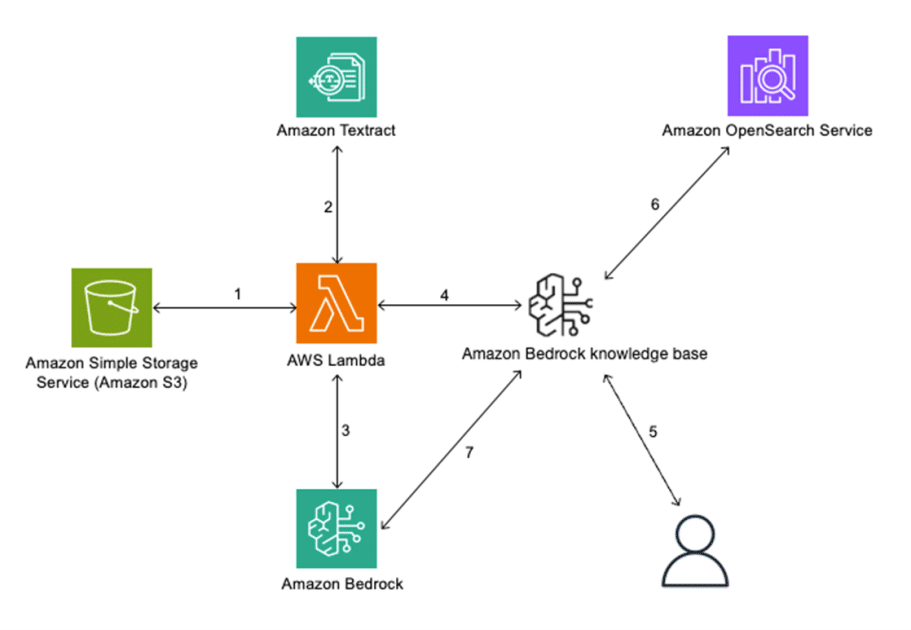
El flujo arquitectónico de la solución actualizada sigue los siguientes pasos: creación de una fuente de datos en Amazon S3, uso de Amazon Textract para extraer datos de PDFs, creación de fragmentos basados en los párrafos del resultado de Textract, incorporación de metadatos adicionales para preservar el contexto, y uso de Amazon OpenSearch Service para seleccionar los fragmentos más similares a la consulta del usuario.
El nuevo mecanismo de división de texto evita dividir oraciones o párrafos a la mitad y elimina elementos ruidosos para proporcionar más contexto útil. Entre los principales elementos de los PDFs se destacan las tablas, imágenes, números de página y encabezados de capítulos. Estos últimos ayudan a etiquetar los fragmentos usando metadatos, mejorando la precisión y velocidad de la extracción.
La división de texto personalizada ofrece varios beneficios, como la preservación del contexto, tamaños de fragmentos flexibles, mejora en el desempeño de la recuperación y una integración sin problemas con otros servicios de AWS. Además, la filtración de metadatos proporciona mejoras significativas en la precisión de las respuestas, aunque requiere conocimiento previo de los nombres de los filtros y sus valores correspondientes.
Finalmente, la mejora en la precisión de los resultados utilizando plantillas de sistema ajustadas y el análisis manual de las respuestas demostró que la estrategia de división de texto personalizada con filtración de metadatos ofrece ventajas significativas sobre métodos fijos.
Esta solución conjunta entre Accenture y AWS afianza su relación estratégica y emplea mecanismos probados para transformar los datos en información útil y precisa, maximizando el potencial de los documentos PDF no estructurados en aplicaciones empresariales.









