Compartir:
Las organizaciones hoy en día están aprovechando los modelos de fundación abiertos (FMs) para desarrollar aplicaciones de inteligencia artificial que se adapten a sus necesidades específicas. Sin embargo, implementar estos modelos puede ser un proceso complejo y demandante, consumiendo hasta un 30% del tiempo total del proyecto. Ello se debe a la necesidad de optimizar meticulosamente los tipos de instancias y configurar parámetros de servicio a través de pruebas exhaustivas, lo que requiere un amplio conocimiento técnico.
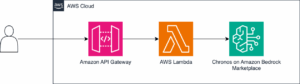
Para simplificar este desafío, Amazon ha lanzado la API Bedrock Custom Model Import. Esta herramienta permite a los desarrolladores subir los pesos de los modelos personalizados, optimizando automáticamente el proceso de implementación. La solución garantiza un despliegue efectivo, escalabilidad automática e incluso la capacidad de escalar a cero. Esto implica que si no hay invocaciones durante cinco minutos, el modelo se apaga automáticamente, ajustando los costos a la utilización real.
Antes de llevar estos modelos a producción, es crucial evaluar su rendimiento. Para ello, existen herramientas de benchmarking que detectan proactivamente problemas y verifican la capacidad de manejo de cargas esperadas. Amazon ha publicado una serie de blogs explorando DeepSeek y los FMs abiertos en Amazon Bedrock Custom Model Import, destacando el uso de herramientas como LLMPerf y LiteLLM para el benchmarking de rendimientos.
LiteLLM, una herramienta versátil, se ofrece como SDK de Python y servidor proxy para acceder a más de 100 FMs diferentes mediante un formato estandarizado. Esta herramienta es esencial para invocar modelos personalizados y optimizar la configuración, simulando un tráfico real para evaluar el rendimiento.
Mediante scripts adecuados, los ingenieros pueden determinar métricas críticas como latencia y rendimiento, fundamentales para el éxito de las aplicaciones de inteligencia artificial. Con LLMPerf, se pueden simular diferentes cargas de tráfico, recopilar métricas en tiempo real y prever problemas en producción, todo ello mientras se estima el costo siguiendo las copias activas del modelo desde Amazon CloudWatch.
Aunque Amazon Bedrock Custom Model Import simplifica la implementación de modelos, el benchmarking sigue siendo vital para predecir el comportamiento en producción. Las organizaciones deben explorar estas herramientas para asegurar una implementación eficiente de sus aplicaciones de inteligencia artificial, optimizando para costo, latencia y rendimiento.