
Compartir:
Monks, la marca operativa digital de S4Capital plc, ha destacado en el ámbito global gracias a su innovación y especialización en servicios de marketing y tecnología. Esta vez, la compañía se ha superado a sí misma con un proyecto que revoluciona la generación de imágenes en tiempo real utilizando los últimos avances en AWS y aceleración de aprendizaje automático.
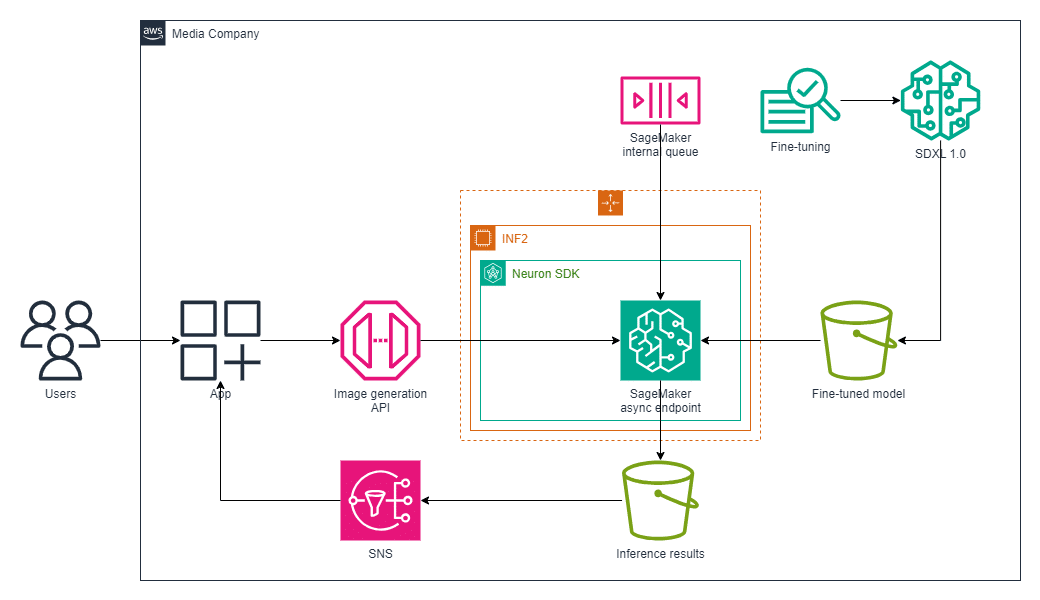
Monks asumió el reto de mejorar la generación de imágenes en tiempo real, un proceso que inicialmente presentaba desafíos significativos en términos de escalabilidad y gestión de costos. Los recursos de computación tradicionales eran costosos y no alcanzaban los requisitos de baja latencia necesarios. Esto impulsó a Monks a explorar soluciones avanzadas de AWS para obtener una computación de alto rendimiento y escalabilidad rentable.
La solución llegó con la adopción de chips AWS Inferentia2 junto con los puntos de inferencia asíncronos de Amazon SageMaker. Estas tecnologías no solo prometían mejorar la velocidad de procesamiento cuatro veces más rápido, sino también reducir los costos gracias a un escalado automático y gestionado.
El proceso comenzó con la afinación del modelo Stable Diffusion XL utilizando imágenes específicas del dominio almacenadas en Amazon S3, empleando Amazon SageMaker JumpStart. Una vez afinado, se creó un punto de inferencia asíncrono empleando los chips AWS Inferentia2, lo que permitió gestionar solicitudes con grandes cargas útiles y tiempos de procesamiento largos manteniendo bajos requerimientos de latencia.
El flujo de trabajo consistía en la creación de puntos de inferencia, manejo de solicitudes, procesamiento y almacenamiento de resultados en Amazon S3, y notificaciones de finalización mediante Amazon SNS. La capacidad de escalar automáticamente las instancias según la demanda y reducir el conteo de instancias a cero durante periodos de inactividad contribuyó significativamente a la reducción de costos.
La implementación de puntos de inferencia asíncronos de SageMaker permitió gestionar cargas variadas de tráfico de manera eficiente, optimizando el uso de recursos. Monks logró procesar un promedio de 27,796 imágenes por hora por instancia, lo que representó una mejora en el rendimiento y una reducción del 60% en los costos por imagen.
El uso de políticas de escalado personalizadas con métricas de Amazon CloudWatch resultó crucial. La adopción de métricas personalizadas permitió a Monks ajustar en tiempo real la capacidad de computación necesaria, optimizando el rendimiento y costo. Estas métricas incluyeron la capacidad de inferencia, el número de solicitudes de inferencia y la tasa de utilización.
El despliegue de AWS Inferentia2 no solo mejoró significativamente el rendimiento de la inferencia, sino que también aumentó la eficiencia y redujo los costos. El modelo optimizado entregaba imágenes en 9.7 segundos, cumpliendo con los estrictos requisitos de latencia de la campaña.
En conclusión, esta implementación de endpoints de inferencia asíncronos de SageMaker con chips AWS Inferentia2 no solo permitió a Monks manejar diferentes cargas de tráfico con eficiencia, sino también reducir costos y mejorar el rendimiento drásticamente. Este enfoque ofrece una guía efectiva para otras aplicaciones de inteligencia artificial generativa, demostrando que la combinación de estas tecnologías es una solución robusta y económica para tareas computacionales intensivas. Monks continúa siendo un socio digital integral, integrando una amplia gama de soluciones y potenciando a las empresas con una producción de contenido más eficiente, experiencias escalables y conocimientos impulsados por IA.









