Compartir:
En un entorno donde la inteligencia artificial está desempeñando un papel crucial, la técnica de Generación Aumentada por Recuperación (RAG) ha surgido como un componente clave para incrementar la precisión y relevancia de las respuestas de los modelos de lenguaje de gran escala. La efectividad de RAG se fundamenta en la calidad del contexto que se proporciona al modelo, contexto que generalmente se extrae de almacenes vectoriales en respuesta a las consultas de los usuarios.
Para optimizar la relevancia de este contexto, el uso del filtrado de metadatos se ha convertido en una herramienta poderosa. Este método permite minimizar el ruido y la información no deseada mediante el pre-filtrado del almacén vectorial según atributos de metadatos específicos.
Sin embargo, en escenarios que implican consultas complejas o una gran cantidad de atributos de metadatos, la creación manual de estos filtros puede ser complicada. Para superar estos desafíos, los modelos de lenguaje de gran escala pueden utilizarse para desarrollar una solución mediante el filtrado inteligente de metadatos.
Amazon ha implementado este enfoque a través de su servicio Bedrock, que permite a los modelos de lenguaje generar filtros de metadatos de manera dinámica a partir de consultas en lenguaje natural. Esto es posible gracias a herramientas de llamado de funciones que facilitan la interacción de los modelos con funciones externas, mejorando la capacidad de los sistemas para gestionar consultas complejas.
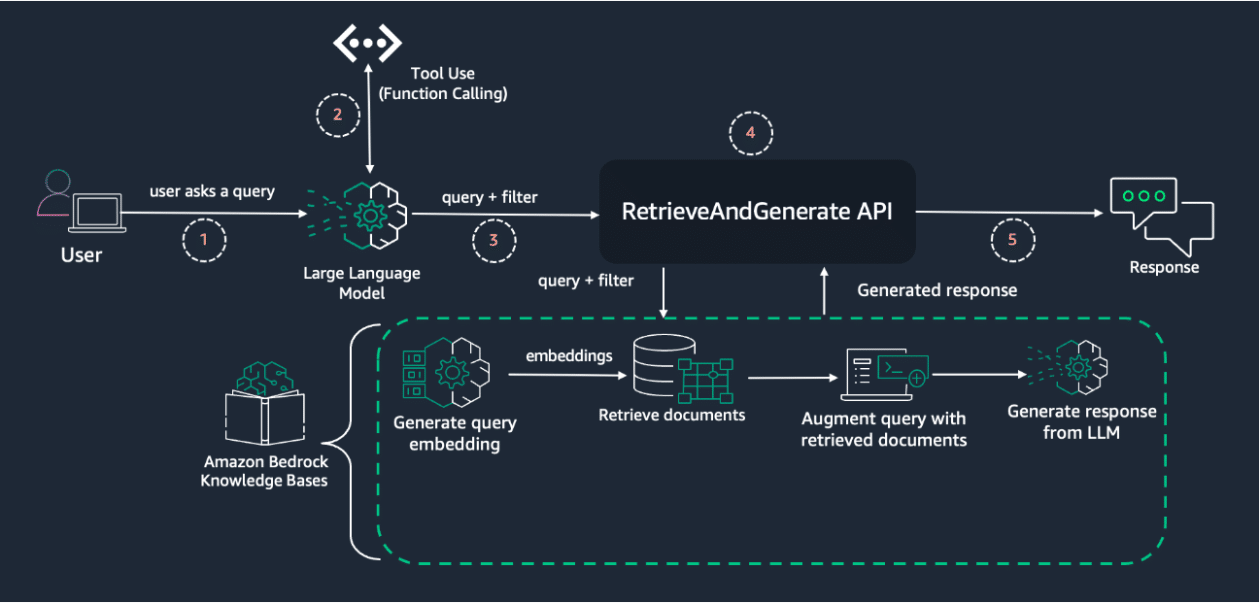
El servicio Amazon Bedrock ofrece a los usuarios una API que les permite acceder a modelos fundacionales de alto rendimiento ofrecidos por empresas líderes en IA. Entre sus características sobresalientes se encuentran las Bases de Conocimiento de Amazon Bedrock, que proporcionan una capacidad RAG totalmente gestionada con potentes capacidades de filtrado de metadatos.
La implementación de este tipo de filtrado puede mejorar notablemente la relevancia de las respuestas en un sistema RAG, así como su capacidad para recordar y contextualizar información. Mediante la integración de Amazon Bedrock y la utilización de modelos de datos Pydantic para validar y estructurar datos, es posible extraer entidades dinámicamente y estructurar filtros de metadatos que optimizan el flujo de recuperación de información.
El proceso comienza con la consulta inicial del usuario, que es procesada por un modelo de lenguaje capaz de extraer los metadatos pertinentes. Estos metadatos luego se utilizan para construir un filtro adecuado, mejorando así la pertinencia de los documentos recuperados.
El filtrado inteligente de metadatos a través de Amazon Bedrock simplifica y potencia la construcción de filtros, ofreciendo un ejemplo de cómo se pueden desarrollar aplicaciones RAG más efectivas y fáciles de usar. Esto permite que las consultas en lenguaje natural sean más intuitivas, y que las respuestas generadas se ajusten mejor a las necesidades específicas de los usuarios.