Compartir:
Amazon ha lanzado al mercado Amazon Bedrock Intelligent Prompt Routing, una herramienta innovadora que promete optimizar la interacción con modelos de lenguaje tanto en términos de costo como de latencia. Después de estar en fase de vista previa desde diciembre, esta nueva función ahora está disponible para todos los usuarios, incorporando mejoras que buscan maximizar la eficiencia en la solicitud y respuesta de modelos de lenguaje.
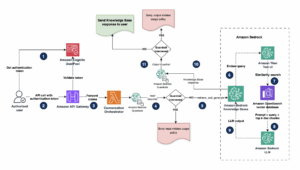
La característica principal de Amazon Bedrock Intelligent Prompt Routing es su capacidad para evaluar dinámicamente la calidad de las respuestas que los distintos modelos pueden ofrecer ante una solicitud concreta. Basado en esta evaluación, el sistema dirige automáticamente la solicitud al modelo que mejor equilibrio ofrece entre costo y calidad de respuesta. Esto supone un avance crucial para aplicaciones de inteligencia artificial generativa, facilitando un enrutamiento automático y eficiente entre distintos modelos de lenguaje grande.
La versión general de la herramienta ha sido mejorada gracias a la retroalimentación de usuarios que participaron en la fase de pruebas y a ensayos internos exhaustivos. Los usuarios pueden optar por utilizar enrutadores de prompts predeterminados ofrecidos por Amazon Bedrock, o bien configurar sus propios enrutadores personalizados para ajustar el rendimiento a sus necesidades individuales. Las soluciones predeterminadas simplifican la implementación al ofrecer configuraciones listas para usar.
Amazon ha añadido más familias de modelos a su catálogo, incluyendo opciones de las conocidas series Nova, Anthropic y Meta, con modelos destacados como Claude y Llama. En esta nueva etapa, los usuarios también tienen la opción de crear enrutadores personalizados, eligiendo específicamente los modelos y métodos de enrutamiento que desean.
Un aspecto destacado de esta herramienta es la reducción lograda en el tiempo de sobrecarga de los componentes añadidos a las solicitudes, disminuyendo en más del 20% y alcanzando aproximadamente 85 milisegundos en el percentil 90. Esto se traduce en una significativa mejora en la latencia y el costo, ya que se prioriza el uso de modelos más económicos sin comprometer la precisión.
Las pruebas internas demuestran que el sistema de enrutamiento no solo cumple con las expectativas de costo, sino que también ofrece ahorros significativos, con reducciones de hasta el 60% en algunas configuraciones de modelos. Los resultados sugieren que esta herramienta puede ofrecer beneficios a aquellos que la implementen adecuadamente en sus casos de uso específicos.
Para facilitar la adopción de esta herramienta, Amazon ha creado recursos y guías disponibles tanto en la consola de gestión de AWS como a través de la interfaz de línea de comandos o API. Estos recursos están diseñados para ayudar a los desarrolladores y empresas a sacar el máximo provecho de esta innovadora solución en sus aplicaciones de inteligencia artificial generativa.