Compartir:
En el ámbito de las aplicaciones de inteligencia artificial generativa, la rapidez en la respuesta se ha convertido en un factor clave tan importante como la inteligencia del propio modelo. Este aspecto es vital para sectores como el servicio al cliente, donde las consultas deben ser resueltas de inmediato, y para desarrolladores que necesitan sugerencias de código al instante. Cada segundo de retraso, conocido técnicamente como latencia, puede afectar significativamente la eficiencia operativa. A medida que más empresas implementan modelos de lenguaje de gran tamaño (LLMs) para tareas críticas, surge un importante desafío: mantener un rendimiento ágil sin comprometer la calidad de los sofisticados resultados que estos modelos pueden ofrecer.
La latencia va más allá de ser una simple incomodidad para el usuario final. En las aplicaciones interactivas de inteligencia artificial, las respuestas retrasadas pueden interrumpir el flujo natural de la conversación, reducir la participación del usuario y, en última instancia, afectar la adopción de soluciones basadas en inteligencia artificial. Este problema se agrava con la creciente complejidad de las aplicaciones modernas que utilizan LLMs, dado que, a menudo, se necesitan múltiples llamados a diferentes modelos para solucionar un único problema, lo que incrementa considerablemente el tiempo total de procesamiento.
Durante el evento re:Invent 2024, se presentó una nueva funcionalidad de inferencia optimizada para la latencia en los modelos de fundación dentro de Amazon Bedrock. Esta innovación ofrece una reducción en la latencia para el modelo Claude 3.5 Haiku de Anthropic y los modelos Llama 3.1 de Meta, en comparación con sus versiones estándar. Esta característica resulta especialmente valiosa para escenarios en los que el tiempo de respuesta es crítico para el negocio, ya que permite que las aplicaciones funcionen de manera más fluida y eficiente bajo condiciones de alta demanda temporal.
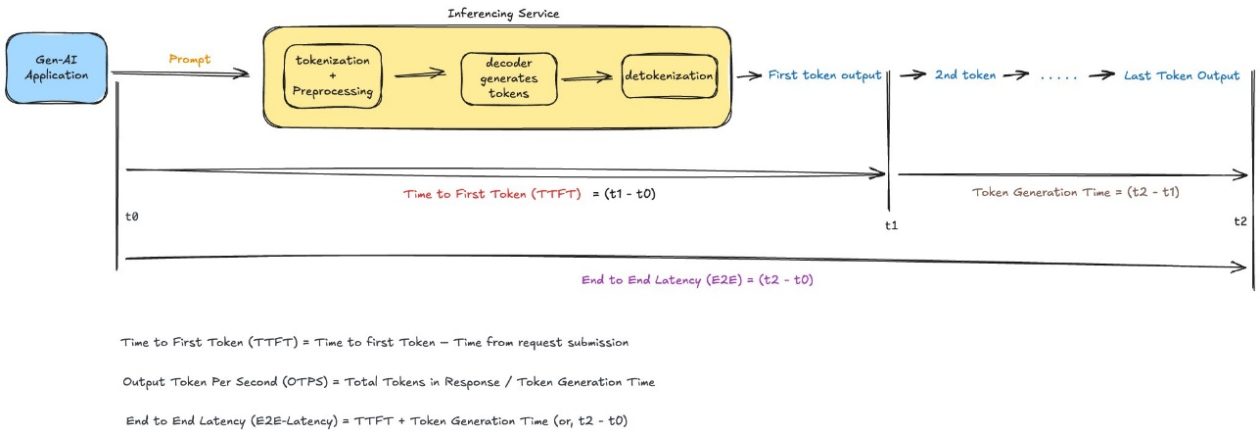
La optimización de la latencia tiene como objetivo mejorar la experiencia del usuario en aplicaciones que utilizan LLMs. En este contexto, la latencia se considera un aspecto multifacético que incluye factores como el tiempo hasta el primer token (TTFT), un indicador de qué tan rápidamente puede comenzar a responder una aplicación tras recibir una consulta. Esta atención al detalle técnico permite que las aplicaciones no solo sean más rápidas, sino también más eficaces en su funcionamiento diario.