
Compartir:
En el panorama actual de la inteligencia artificial, los modelos de lenguaje a gran escala (LLMs) se han establecido como piezas clave en las investigaciones más avanzadas. Estos sistemas, capaces de comprender y generar lenguaje natural con notable agilidad, han experimentado un crecimiento significativo en su capacidad operativa y eficiencia. La carrera por mejorar el entrenamiento de LLMs se ha intensificado, con organizaciones en todo el mundo esforzándose por superar las barreras de tamaño y rendimiento de estos modelos.
En 2023, Amazon SageMaker dio un paso crucial en esta dirección al integrar en su plataforma las instancias P5, diseñadas para manejar el entrenamiento distribuido de modelos grandes. Estas instancias son compatibles con hasta ocho GPUs NVIDIA H100 Tensor Core, lo que permite a las organizaciones aprovechar tecnologías de red de alto ancho de banda como EFA para entrenar modelos en paralelo a través de múltiples nodos. Este avance ha permitido a las organizaciones acelerar notablemente la velocidad y eficiencia de sus entrenamientos de modelos.
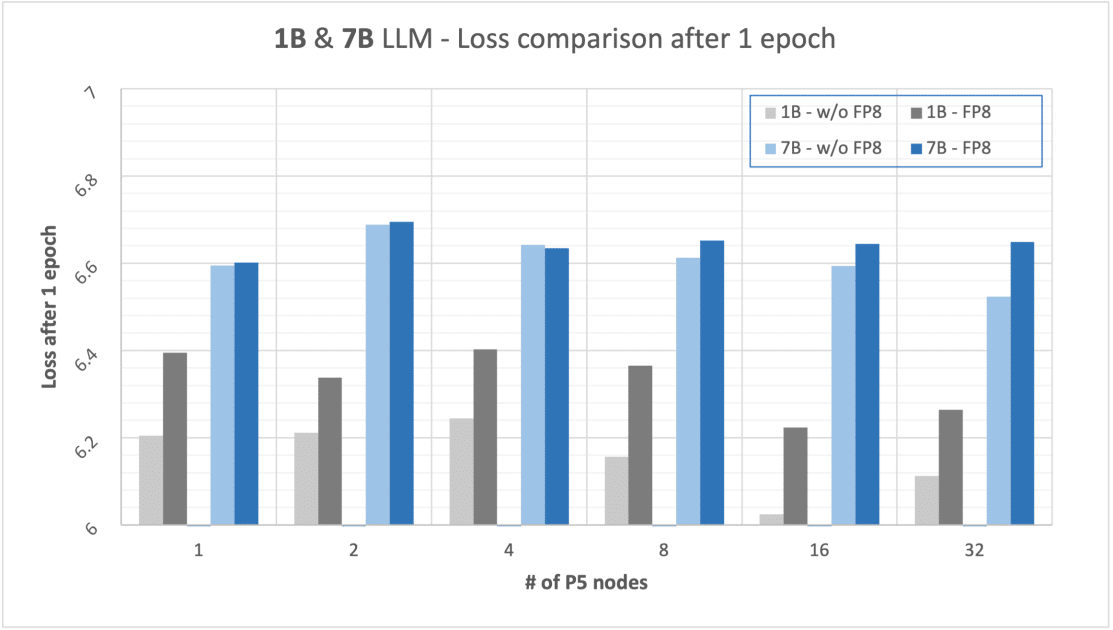
Una de las innovaciones más destacadas ha sido la incorporación de la precisión FP8 en la formación de LLMs, utilizando las potencialidades de las GPUs NVIDIA H100. Este tipo de precisión ha demostrado ser una herramienta revolucionaria, ya que optimiza el uso de memoria y acelera el proceso de computación sin sacrificar la calidad del modelo. La reducción en el tamaño de los datos y los requerimientos computacionales posibilita entrenar modelos más grandes con el mismo hardware, o bien reducir los tiempos de entrenamiento sin perder eficacia.
Pruebas recientes con modelos de 1B y 7B parámetros han evidenciado que el empleo de FP8 eleva la velocidad de entrenamiento en un 13% y 18% respectivamente. Sin embargo, este avance viene acompañado de una ligera degradación en la pérdida del modelo después de un epoch, que es de apenas un 3% más alta para modelos de 1B y un 2% para los de 7B al compararlos con los entrenamientos estándar. En términos de costo-beneficio, las ventajas superan significativamente a las desventajas leves en la precisión.
Este cambio hacia la adopción de FP8, junto con las instancias P5 de SageMaker, representa un progreso importante en la evolución de la formación de LLMs, invitando a más investigadores y organizaciones a implementar estas técnicas. Los beneficios no solo se limitan al campo de procesamiento del lenguaje, sino que también se extienden a otras disciplinas de investigación, como la visión por computadora y el aprendizaje por refuerzo, al permitir el entrenamiento de modelos complejos de manera más rápida y eficiente. Además, se ha comprobado que los modelos con activaciones en FP8 ofrecen un rendimiento superior en la inferencia.
En resumen, los avances en precisión FP8 y las instancias P5 marcan un hito en la optimización y eficiencia del entrenamiento de modelos de lenguaje a gran escala. Estos desarrollos no solo consolidan las bases para futuras innovaciones en la inteligencia artificial, sino que también facilitan caminos hacia la implementación de optimizaciones en diversas áreas del conocimiento.









