
Compartir:
Las aplicaciones de Retrieval Augmented Generation (RAG) están ganando terreno dentro del ámbito de la inteligencia artificial, ofreciendo la capacidad de proporcionar información contextual que mejora significativamente el rendimiento de las tareas generativas. No obstante, la implementación de estas aplicaciones requiere especial atención hacia la seguridad de los datos, especialmente los datos sensibles, como la información personal identificable (PII), la información de salud protegida (PHI) y los datos comerciales confidenciales.
La protección de estos datos es esencial, dado que fluyen a través de los sistemas RAG, lo cual puede acarrear riesgos significativos y potenciales brechas de seguridad si no se manejan adecuadamente. Para sectores como el de la salud, instituciones financieras y otras organizaciones que manejan información confidencial, estos riesgos no solo podrían significar violaciones de cumplimiento regulatorio, sino también la pérdida de confianza de sus clientes.
Para abordar estos desafíos, el desarrollo de un modelo de amenaza integral en aplicaciones de inteligencia artificial generativa resulta crucial. Este modelo permite identificar posibles vulnerabilidades relacionadas con la fuga de datos sensibles, inyecciones de comandos y accesos no autorizados. En este sentido, AWS ofrece una gama completa de estrategias de seguridad para IA generativa, que son esenciales al construir modelos de amenazas correspondientes.
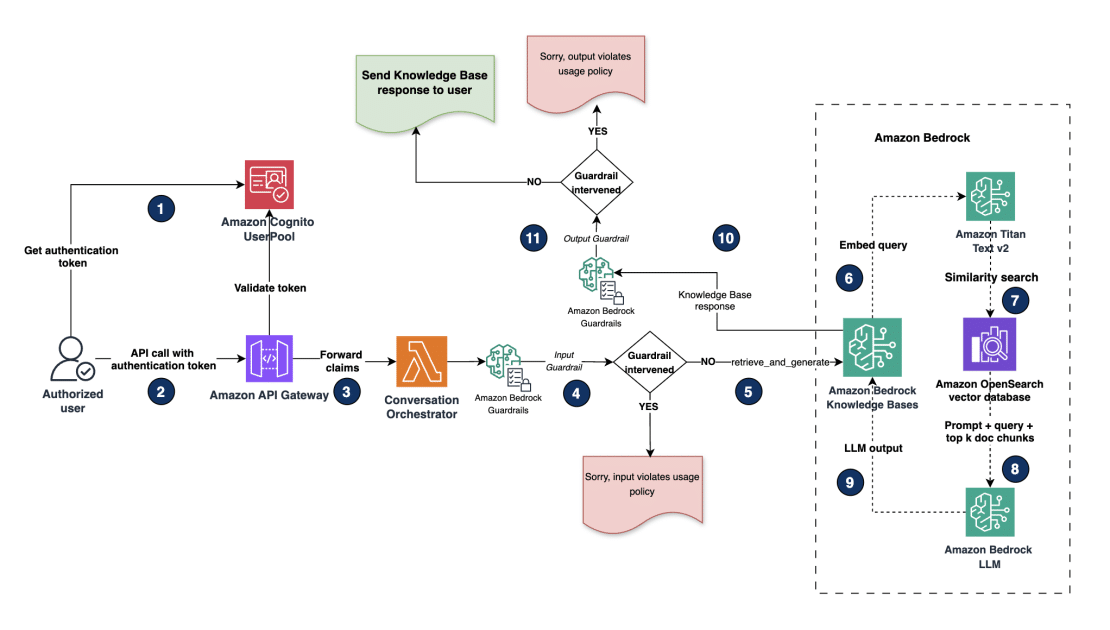
Una de las soluciones más avanzadas viene de la mano de Amazon Bedrock. Este servicio facilita la gestión del flujo de trabajo RAG, permitiendo que las organizaciones integren datos contextuales privados a sus modelos y agentes, logrando así respuestas más precisas y adaptadas a necesidades específicas. Con Amazon Bedrock Guardrails, se pueden implementar salvaguardias personalizadas que ayudan a redactar información sensible, protegiendo así la privacidad de los datos.
El flujo de trabajo de RAG se compone de dos fases críticas: la ingestión y la recuperación aumentada. Durante la ingestión, los datos no estructurados son preprocesados y transformados en texto, que posteriormente se divide en fragmentos. Estos fragmentos son codificados y almacenados en vector stores, como el Amazon OpenSearch Service. En la fase de recuperación aumentada, las consultas del usuario son codificadas y se utiliza este código para buscar fragmentos semánticamente similares, recuperando así la información más relevante.
No obstante, es vital que la información sensible se sanitice antes del proceso de ingestión para evitar su recuperación indebida por usuarios no autorizados. Para tal fin, se proponen dos patrones arquitectónicos sólidos: la redacción de datos a nivel de almacenamiento y el acceso basado en roles. La redacción de datos implica el filtrado de información sensible antes de su almacenamiento, mientras que el acceso basado en roles permite control selectivo del acceso a los datos según perfiles y permisos, especialmente en entornos como el de la salud, donde es crucial diferenciar entre roles administrativos y no administrativos.
En resumen, mientras que las aplicaciones de RAG proporcionan recursos valiosos para mejorar la eficacia de la inteligencia artificial generativa, también exigen una atención meticulosa en la protección de datos sensibles. Implementar estos enfoques no solo mitiga riesgos, sino que también refuerza la confianza del cliente y asegura el cumplimiento normativo, marcando así un paso esencial hacia el desarrollo seguro y responsable de la inteligencia artificial.









