Compartir:
Un reciente informe de McKinsey & Company ha estimado que la inteligencia artificial generativa podría aportar entre 2.6 y 4.4 billones de dólares en valor a la economía global. Este impresionante potencial económico está impulsando a numerosas empresas a desarrollar aplicaciones de inteligencia artificial generativa en Amazon Web Services (AWS), particularmente en áreas como la gestión de operaciones con clientes, marketing, ventas, ingeniería de software e investigación y desarrollo.
Sin embargo, mientras las empresas se aventuran en este emocionante campo, muchos líderes en gestión de productos y arquitectos empresariales están tratando de entender mejor los costos involucrados y las estrategias para optimizarlos. Este artículo aborda estas consideraciones de costo, asumiendo que los lectores ya tienen un conocimiento básico sobre modelos de base, modelos de lenguaje grandes, tokens y bases de datos vectoriales en AWS.
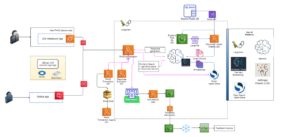
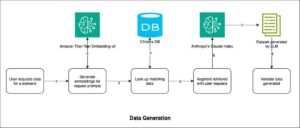
Entre los marcos más utilizados en la inteligencia artificial generativa se encuentra la Generación Aumentada por Recuperación (RAG). Este método permite a los modelos de lenguaje responder a preguntas específicas basadas en datos corporativos, incluso si no fueron específicamente entrenados con esa información. En este contexto, se exploran los pilares de optimización de costos y rendimiento, que abarcan la selección, elección y personalización de modelos, el uso de tokens, los planes de precios de inferencia, entre otros.
La selección del modelo adecuado implica identificar el que mejor se adapte a las necesidades específicas, seguido por una validación con conjuntos de datos de alta calidad. La elección del modelo se centra en seleccionar el más adecuado basado en características de precios y rendimiento, mientras que la personalización busca modificar modelos preexistentes con datos de entrenamiento para maximizar la eficiencia.
El análisis del uso de tokens resulta crucial, dado que los costos de operar un modelo de IA generativa dependen directamente del número de tokens procesados. Implementar limitaciones en el número de tokens y estrategias de almacenamiento en caché puede ayudar a mitigar los costos.
En términos de planes de precios de inferencia, AWS ofrece varias opciones como la modalidad bajo demanda, que suele ser ideal para la mayoría de los modelos, y el rendimiento provisionado, el cual garantiza un nivel específico de rendimiento a un costo generalmente más elevado. Otros factores importantes incluyen medidas de seguridad como filtros de contenido, el costo asociado al uso de bases de datos vectoriales y las estrategias de fragmentación de datos, que pueden afectar tanto la precisión como los costos generales.
Los costos pueden variar significativamente dependiendo del volumen de preguntas que una aplicación de asistente virtual reciba. Se presentan ejemplos que destacan esta variabilidad, siendo que un modelo de lenguaje como Claude 3 de Anthropic puede generar costos anuales que oscilan entre 12,577 y 134,252 dólares.
Finalmente, se discuten las implicaciones del uso de servicios como Amazon Bedrock para acceder a modelos de alto rendimiento, así como el uso de guardrails que ayudan a controlar el contenido y mejorar la seguridad de las aplicaciones. Esto es especialmente fundamental en un entorno donde un asistente virtual podría interactuar sobre una amplia gama de temas, y se debe prevenir la generación de contenido inapropiado.
A medida que la inteligencia artificial generativa sigue evolucionando, es esencial que las organizaciones se mantengan actualizadas sobre cómo pueden fluctuar estos costos y las formas de optimizarlos para maximizar su valor. En futuras entregas, se abordarán aspectos relacionados con la estimación del valor comercial y los factores que la influencian.