Compartir:
El entrenamiento de modelos avanzados, como el Llama 3 con sus imponentes 70 mil millones de parámetros, se presenta como uno de los desafíos más exigentes para la tecnología de la computación moderna. Para poner en marcha este proceso que demanda altos recursos, se necesita un sistema distribuido capaz de integrar cientos, si no miles, de instancias aceleradas que operan durante semanas o incluso meses para completar un único proyecto. Por ejemplo, para el preentrenamiento del modelo Llama 3, se utilizaron 15 billones de tokens de entrenamiento, lo cual demandó unas asombrosas 6.5 millones de horas de GPU H100. Un sistema compuesto por 256 instancias de Amazon EC2 P5, equipadas con GPUs NVIDIA H100, necesitaría aproximadamente 132 días para concluir esta tarea.
Los trabajos de entrenamiento distribuidos se ejecutan de forma sincrónica, lo que significa que para cada paso de entrenamiento, todas las instancias participantes deben completar sus cálculos antes de avanzar. Esto incrementa la vulnerabilidad del sistema, ya que cualquier fallo en una única instancia puede obstaculizar el trabajo total. Con el crecimiento del clúster, la probabilidad de fallos también aumenta debido a la cantidad de componentes de hardware involucrados. Cada falla no solo representa la pérdida de horas de GPU, sino también de tiempo valioso de ingeniería para solucionar el problema, lo que puede traducirse en períodos de inactividad que retrasan el avance. Para evaluar la fiabilidad, los equipos de ingeniería recurren a métricas como el tiempo medio entre fallos (MTBF), que mide el tiempo promedio de operación entre fallos.
Documentar estos fallos es vital para entender la MTBF típica en modelos de frontera a gran escala. Por ejemplo, en el entrenamiento del modelo OPT-175B por Meta AI, que implicó 992 GPUs A100, se registraron 35 reinicios manuales y más de 70 automáticos en dos meses, resultando en una tasa de fallo de 0.0588% por hora. Otro caso, el entrenamiento de Llama 3.1 en 16,000 GPUs H100, registró 417 fallos en 54 días, con una tasa de 0.0161% por hora. Estos ejemplos sugieren que, en una hora de entrenamiento distribuido a gran escala, aproximadamente el 0.02% a 0.06% de las instancias pueden fallar.
El tamaño del clúster también afecta la fiabilidad: a mayor tamaño, mayor es la entropía del sistema y menor el MTBF. Con una tasa de fallo de 0.04% por hora, un sistema de 512 instancias podría experimentar un fallo cada 5 horas. Este aumento de fallos representa un desafío considerable para los equipos de ingeniería.
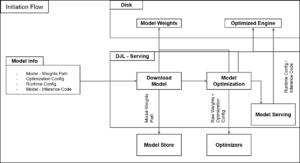
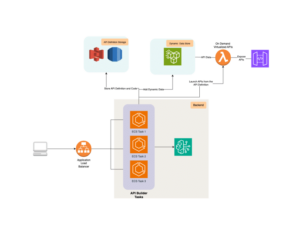
El proceso de resolución de fallos suele ser largo, comenzando con un análisis de la causa, seguido por la reparación o el reemplazo del hardware y la recuperación del sistema. La detección rápida de fallos y tiempos de reparación más cortos son cruciales para reducir el tiempo total de entrenamiento. En este contexto, Amazon SageMaker HyperPod emerge como una solución destacada, que automatiza la detección y el reemplazo de instancias defectuosas, permitiendo reanudar el entrenamiento desde el último punto guardado, mejorando así la eficiencia operativa.
Las mediciones empíricas sugieren que SageMaker HyperPod podría reducir el tiempo total de entrenamiento en un 32% en un clúster de 256 instancias con una tasa de fallo del 0.05%. Esto se traduce en un ahorro de aproximadamente 25 millones de dólares en costos de entrenamiento para proyectos que requieren 10 millones de horas GPU.
La tremenda complejidad y los recursos necesarios para entrenar modelos de frontera hacen fundamental que las empresas busquen soluciones eficientes que les permitan centrarse en la innovación en vez de en la gestión de infraestructura. SageMaker HyperPod ofrece a los equipos de inteligencia artificial la confianza necesaria para entrenamientos prolongados, asegurando que cualquier fallo de hardware sea detectado y resuelto automáticamente, minimizando así las interrupciones en sus trabajos de aprendizaje automático.