
Compartir:
Las empresas se encuentran bajo una presión creciente para demostrar el retorno de la inversión en sus proyectos de inteligencia artificial, ya sea mediante el aprendizaje automático predictivo o la IA generativa. Sin embargo, solo el 54% de los prototipos de aprendizaje automático llegan a la fase de producción, y apenas un 5% de los casos de uso de IA generativa alcanza este hito. La clave no es solo llevar los proyectos a producción, sino garantizar la precisión y el rendimiento del modelo, requisitos que demandan un sistema escalable y confiable con alta precisión y baja latencia.
Un ejemplo claro de la necesidad de baja latencia es la detección de fraudes, que requiere decisiones tan rápidas como el tiempo que tarda en leerse una tarjeta de crédito en una terminal. Con el incremento de casos de fraude, más organizaciones buscan implementar sistemas efectivos de detección. En 2023, las pérdidas por fraude en Estados Unidos superaron los 10 mil millones de dólares, lo que representa un aumento del 14% respecto al año anterior. Se proyecta que el fraude global en el comercio electrónico podría sobrepasar los 343 mil millones de dólares para 2027.
Desarrollar y gestionar una aplicación de IA precisa y confiable para combatir este problema es un desafío inmenso. Los equipos de aprendizaje automático acostumbran a comenzar conectando manualmente diversos componentes de infraestructura. Este enfoque puede parecer simple al trabajar con datos por lotes, pero se complica al implementar fuentes de datos en tiempo real, pasando de inferencias por lotes a un servicio en tiempo real.
Los ingenieros deben construir y orquestar tuberías de datos, atender las diversas necesidades de procesamiento de cada fuente, gestionar la infraestructura de cómputo y crear una infraestructura fiable para las inferencias. Sin las capacidades adecuadas, la arquitectura resultante sería compleja y difícil de manejar.
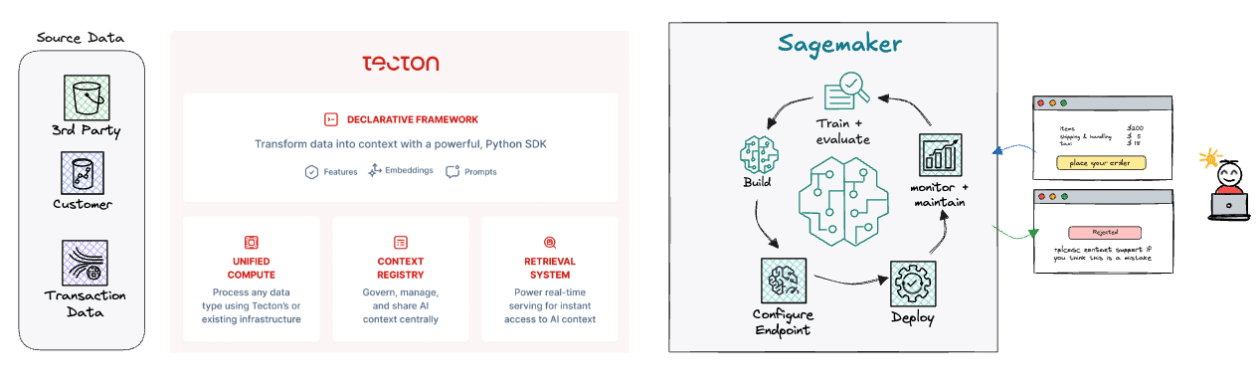
Para simplificar esta complejidad, Tecton y Amazon SageMaker facilitan el trabajo de ingeniería requerido para las aplicaciones de IA en producción en tiempo real, acelerando el tiempo hasta lograr valor y permitiendo a los equipos de ingeniería centrarse en desarrollar nuevas características en lugar de luchar por mantener la infraestructura existente.
Tecton proporciona un marco de trabajo declarativo accesible para definir las transformaciones necesarias en las características de los modelos, construyendo las tuberías necesarias para calcular, gestionar y servir estas características. Su integración con almacenes de datos en disco y en memoria, así como el soporte de caché en memoria para ofrecer características a través de una API REST de baja latencia, responde a las exigencias de casos de uso en tiempo real como la detección de fraudes.
Con esta infraestructura, es posible completar un caso práctico de detección de fraudes mediante la integración de API de terceros, la extracción de datos históricos y características de comportamiento del usuario, la comparación de actividades recientes y el envío de la información a un modelo en SageMaker que evalúa la validez de la transacción.
Tecton también abre nuevas posibilidades para casos de uso de IA generativa, permitiendo la integración de estas capacidades en aplicaciones existentes para ofrecer experiencias enriquecidas, como el uso de modelos de lenguaje de gran escala para la asistencia al cliente con información contextual relevante.
En resumen, Tecton y SageMaker permiten a los equipos de IA desplegar aplicaciones de alto rendimiento en tiempo real sin la complejidad de la ingeniería de datos, facilitando un camino más eficiente hacia la creación de valor a través de la inteligencia artificial.









