Compartir:
Amazon Bedrock ha introducido una nueva funcionalidad denominada Knowledge Bases, diseñada para optimizar los flujos de trabajo de Generación Aumentada por Recuperación (RAG). Esta herramienta totalmente gestionada, que abarca desde la ingestión hasta la recuperación y la augmentación de prompts, simplifica el proceso al eliminar la necesidad de crear integraciones personalizadas con fuentes de datos y gestionar flujos de datos de manera independiente. Para maximizar su potencial, es esencial realizar pruebas frecuentes y ajustar las configuraciones, ya que no existe un único camino para la optimización del rendimiento en las bases de conocimiento.
Un artículo reciente desglosa las etapas cruciales para evaluar la eficacia de estas bases de conocimiento. La evaluación se centra en dos fases principales: la recuperación y la generación de respuestas. Durante la recuperación, el sistema extrae partes relevantes de documentos en función de una consulta específica, añadiéndolos como contexto al prompt final. La fase de generación consiste en enviar este prompt, junto con el contexto recuperado, a un modelo de lenguaje grande (LLM), para devolver posteriormente la respuesta al usuario.
Para garantizar una recuperación eficiente, se utilizan dos métricas básicas: la relevancia del contexto, que evalúa si la información recuperada responde adecuadamente a la consulta, y la cobertura del contexto, que mide cuán completas son las respuestas frente a una base de datos objetiva. Estas métricas se calculan comparando resultados con respuestas esperadas en un conjunto de datos de prueba predeterminado.
Superada la validación de la recuperación de contexto relevante, se procede a medir la generación de respuestas. Amazon Bedrock ofrece un marco de evaluación integral que aborda ocho métricas esenciales, abarcando tanto la calidad de las respuestas como principios de inteligencia artificial responsable. Las métricas de calidad incluyen aspectos como la utilidad, la corrección y la coherencia lógica, mientras que las métricas de inteligencia responsable analizan la presencia de contenido potencialmente dañino o estereotipado y la habilidad del sistema para rechazar preguntas inapropiadas.
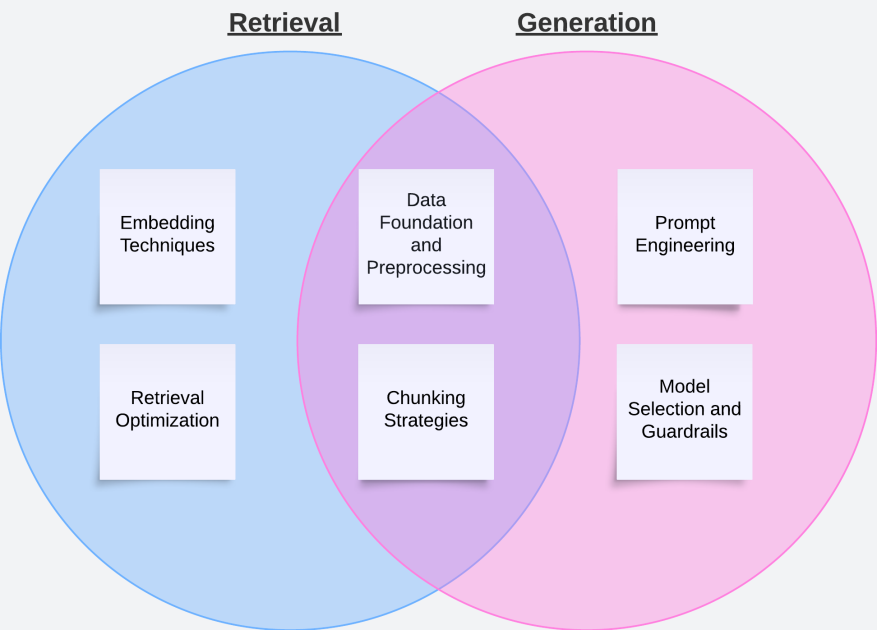
La construcción de un conjunto robusto de datos de prueba se considera vital para una evaluación eficaz, recomendándose el uso de datos anotados por humanos, la creación de datos sintéticos mediante LLMs y la implementación de una estrategia de mejora continua apoyada en la retroalimentación de los usuarios. A lo largo del proceso de optimización, se enfatiza un equilibrio entre técnicas de mejora del rendimiento y un enfoque iterativo, que permita realizar ajustes precisos y significativos.
En conclusión, optimizar las Bases de Conocimiento de Amazon Bedrock es un proceso iterativo que requiere pruebas constantes y ajustes detallados. El éxito se alcanza mediante el uso de técnicas como la ingeniería de prompts y el chunking para optimizar las etapas de recuperación y generación. Monitorizar las métricas clave a lo largo del proceso asegura que las optimizaciones cumplan las expectativas de la aplicación.