Compartir:
En un mundo empresarial cada vez más dependiente de la tecnología, la detección de anomalías se ha convertido en un componente esencial para garantizar la seguridad de los sistemas y optimizar el rendimiento. En respuesta a esta necesidad, se ha presentado una nueva solución que promete revolucionar este ámbito mediante el uso de Amazon SageMaker. Esta plataforma ofrece un enfoque automatizado para procesar datos de registros, ejecutar múltiples iteraciones de entrenamiento y desarrollar modelos de detección de anomalías altamente eficientes. Todo ello se registra en el Amazon SageMaker Model Registry, facilitando su acceso y uso por parte de los clientes.
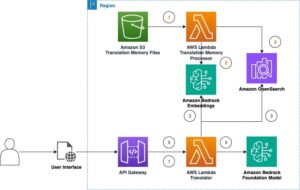
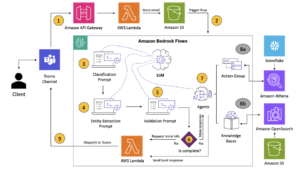
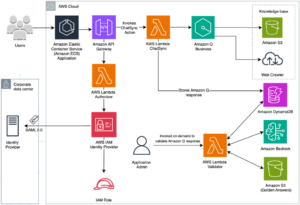
Detectar anomalías en los registros implica la identificación de datos atípicos que puedan indicar problemas de ejecución o actividades sospechosas dentro de los sistemas. Este proceso comienza transformando los registros en vectores comprensibles para las máquinas, que luego son utilizados para entrenar algoritmos de aprendizaje automático personalizados. No obstante, uno de los mayores retos es el ajuste de hiperparámetros, una tarea fundamental para el éxito de los modelos, pero que tradicionalmente consume mucho tiempo y es compleja, especialmente con grandes volúmenes de datos.
Amazon SageMaker ofrece una solución eficiente a este desafío mediante el uso de SageMaker Pipelines. Esta herramienta permite automatizar cada fase del proceso, desde la ingesta de datos, pasando por el procesamiento y el entrenamiento, hasta la modelación final, creando un flujo de trabajo integrador y eficaz. Esta automatización no solo reduce drásticamente el tiempo requerido, sino que también proporciona una escalabilidad esencial para las empresas que operan con datos en constante expansión.
El sistema propuesto sigue una serie de pasos precisos: inicialmente, los datos de entrenamiento se almacenan en un bucket de Amazon S3. Luego, SageMaker procesa estos datos con scripts personalizados que pueden ser ejecutados de forma descentralizada. Seguidamente, se realiza el ajuste de hiperparámetros mediante múltiples iteraciones para identificar el modelo más eficiente.
Una vez entrenado, el modelo se registra en el Amazon SageMaker Model Registry. Esto permite a otros usuarios, como controladores de calidad, usarlo para comparar diferentes modelos y evaluar su eficiencia antes de aplicarlos en un entorno de producción.
Los expertos en el campo destacan que esta metodología no solo simplifica significativamente el proceso de detección de anomalías, sino que también optimiza la utilización de los recursos computacionales. Este avance permite a las empresas reaccionar con mayor rapidez a posibles problemas de seguridad o de rendimiento. Al automatizar la carga de trabajo, los equipos de data science pueden concentrarse en tareas de mayor valor, como la innovación y la mejora continua de los modelos. Las nuevas capacidades de SageMaker representan un avance notable en el ámbito de la inteligencia artificial y el aprendizaje automático, facilitando el camino para un futuro más seguro y eficiente en el manejo de datos.