Compartir:
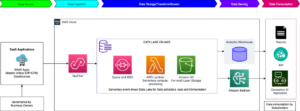
El desarrollo de una línea de despliegue para aplicaciones de inteligencia artificial generativa (IA) a gran escala presenta un desafío formidable debido a las complejidades y requisitos únicos de estos sistemas. Los modelos de IA generativa están en constante evolución, con nuevas versiones y actualizaciones que se lanzan con frecuencia. Gestionar y desplegar estas actualizaciones en una pipeline de despliegue a gran escala, manteniendo la consistencia y minimizando el tiempo de inactividad, es una tarea significativa. Estas aplicaciones requieren ingesta continua, preprocesamiento y formateo de grandes cantidades de datos provenientes de diversas fuentes, lo que hace necesario construir pipelines de datos robustas capaces de manejar esta carga de trabajo de manera confiable y eficiente.
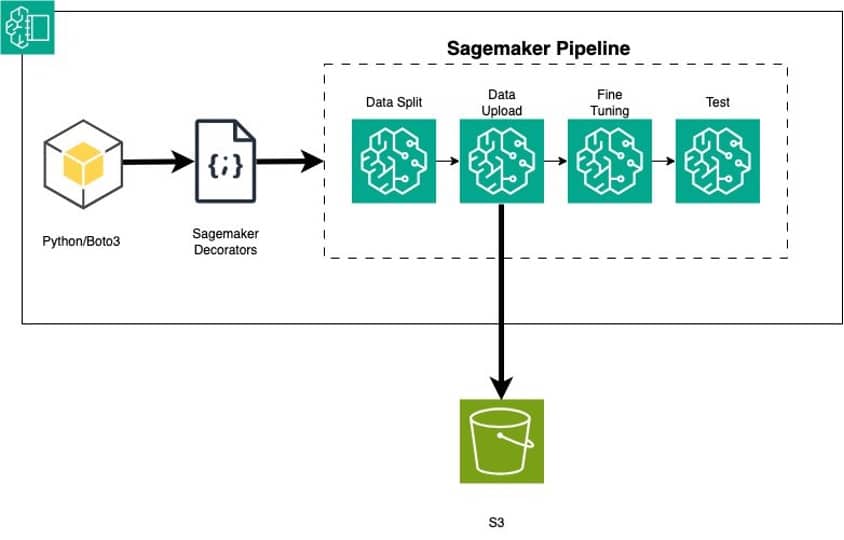
Lograr esto a gran escala requiere inversiones significativas en recursos, experiencia y colaboración transversal entre múltiples perfiles, como científicos de datos y desarrolladores de aprendizaje automático (ML) que se enfocan en desarrollar modelos ML, y los ingenieros de operaciones de aprendizaje automático (MLOps) que mejoran los tiempos de entrega y reducen defectos. La clave radica en convertir el código Python que ajusta finamente un modelo de IA generativa en Amazon Bedrock a un workflow reutilizable utilizando los decoradores de Amazon SageMaker Pipelines.
SageMaker Pipelines permite definir y orquestar los diversos pasos involucrados en el ciclo de vida de ML, como el preprocesamiento de datos, el entrenamiento de modelos, la evaluación y el despliegue. Esto agiliza el proceso y proporciona consistencia en las diferentes etapas de la pipeline. Además, SageMaker Pipelines gestiona la versión de los modelos y el seguimiento de la genealogía, permitiendo reproducir y auditar las versiones de los modelos.
El uso de decoradores en SageMaker Pipelines facilita la conversión del código local de ML escrito en Python a uno o varios pasos dentro de una pipeline. Dado que Amazon Bedrock se puede acceder como una API, los desarrolladores que no están familiarizados con Amazon SageMaker pueden implementar una aplicación en Amazon Bedrock o hacer ajustes finos escribiendo un programa en Python.
El proceso tiene tres pasos fundamentales:
1. Escribir el código en Python para preprocesar, entrenar y probar un modelo de lenguaje grande (LLM) en Amazon Bedrock.
2. Añadir funciones decoradas con @step para convertir el código Python a una pipeline de SageMaker.
3. Crear y ejecutar la pipeline de SageMaker.
El uso de SageMaker Model Building Pipelines proporciona una herramienta para construir pipelines de ML aprovechando la integración directa con SageMaker, permitiendo crear pipelines de orquestación y gestionar los recursos de manera automática. Además, SageMaker Studio ofrece un entorno para gestionar la experiencia integral de las pipelinas de SageMaker, mejorando la eficiencia operativa de ML.
Durante la implementación, se detallan pasos técnicos específicos, como la carga de datos, partición de datos, subida de datos a Amazon S3, entrenamiento del modelo, creación de un throughput provisionado, y prueba del modelo. También se menciona la importancia de limpiar después de la ejecución de los ejemplos para evitar costos adicionales.
En conclusión, MLOps se enfoca en optimizar, automatizar y monitorear modelos de ML durante su ciclo de vida. La colaboración entre diversos perfiles es crucial para operacionalizar los modelos desde la investigación hasta el despliegue y mantenimiento. SageMaker Pipelines ofrece la creación y gestión de workflows de ML con características adicionales de seguimiento y reutilización de pasos, todo desde un entorno unificado en Amazon SageMaker Studio.
Amazon Web Services proporciona soluciones gestionadas, como Amazon Bedrock y SageMaker, para ayudar en el despliegue y servicio de modelos fundacionales existentes o en la creación y ejecución de modelos personalizados. Este enfoque mejora significativamente la eficiencia operativa para proyectos de IA a gran escala, asegurando un manejo eficaz y optimizado de recursos y procesos.